Vrstvy ISO/OSI a teorie síťování
| Stránky: | CZ.NIC Moodle |
| Kurz: | Síťování v Linuxu |
| Kniha: | Vrstvy ISO/OSI a teorie síťování |
| Vytiskl(a): | Nepřihlášený host |
| Datum: | pondělí, 27. července 2026, 04.13 |
L1 a L2 - Ethernet, WiFi a PPP
O první a druhé vrstvě má smysl uvažovat společně. Z hlediska linuxového jádra je první a druhá síťová vrstva zpravidla skryta za ovladačem konkrétní síťové periferie - NIC (network interface card). Rozdělení je takové, že první vrstva je, až na naprosté výjimky, čistě hardwarová záležitost. Druhou vrstvou vede nepříliš zřetelná hranice mezi funkcemi, které jsou realizované v hardwaru, ve firmwaru nebo v ovladači periferie v jádře operačního systému.
Ethernetový síťový adaptér
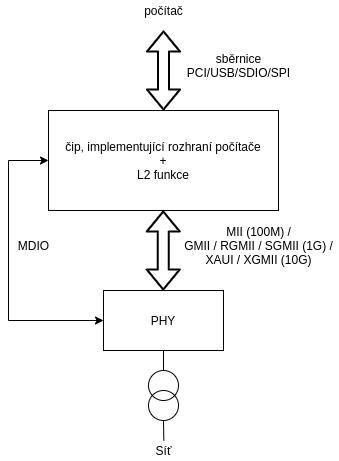
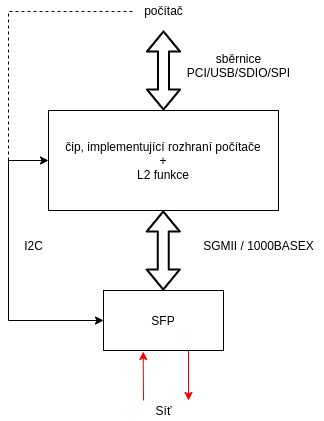
Příkladem může být moderní ethernetová karta - ta má zpravidla L1 implementovanou v podobě čipu PHY, který zajišťuje vygenerování signálu z dat, která přicházejí přes *MII (Media Independent Interface) z čipu, který implementuje L2, do média a naopak převádí signál z média a na data na MII sběrnici. Sběrnice mezi PHY a zbytek síťové karty jsou podle rychlosti AUI, MII, GMII, RGMII, SGMII, XGMII a další. Alternativně může být síťová karta místo PHY vybavená SFP či SFP+ klecí pro optický, nebo jiný modul s rozhraním dle příslušného standardu.
L2 část síťové karty je zpravidla implementováná čipem, na kterém může být různě velká část funkcionality implementována firmwarem. Firmware lze zpravidla updatovat z operačního systému přes příslušný ovladač zařízení. V některých případech (ale to se týká zejména WiFi karet) je nutné firmware nahrát ze souboru do síťové karty při každém startu systému.
Mimo samotné MII rozhraní mezi PHY respektive mezi SFP modulem a L2 částí síťové karty je zpravidla použito ještě nezávislé pomalejší rozhraní pro přenos stavových informací a nastavení parametrů PHY. Zpravidla se pro PHY používá rozhraní MDIO. Do SFP modulu zase vede I2C sběrnice, která slouží k identifikaci modulu a správnému nastavení parametrů přenosu.
Metalická síťová karta tedy vypadá obvykle takto:
Naproti tomu stojí karta s optickým SFP modulem:
Odkazy:
- https://en.wikipedia.org/wiki/PHY
- https://en.wikipedia.org/wiki/Small_form-factor_pluggable_transceiver
- https://en.wikipedia.org/wiki/Management_Data_Input/Output
Fyzická vrstva je přes rozhraní MDIO přístupná z linuxového userspacu pomocí nástroje mii-tool. Tímto nástrojem je možné zjistit stav a měnit nastavení fyzické vrstvy, tedy zejména rychlost, duplexitu, autonegotiation a podporu pause-rámců pro Ethernet flow control. Příklad:
$ sudo mii-tool -v enx34d0b8c0b534
enx34d0b8c0b534: negotiated 1000baseT-FD flow-control, link ok
product info: vendor 00:07:32, model 0 rev 0
basic mode: autonegotiation enabled
basic status: autonegotiation complete, link ok
capabilities: 1000baseT-FD 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD
advertising: 1000baseT-FD 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD flow-control
link partner: 1000baseT-FD 100baseTx-FD 100baseTx-HD 10baseT-FD 10baseT-HD flow-control
Odkazy:
Nastavení parametrů L2 části síťové karty je specifické pro každý konkrétní typ karty a její ovladač. V Linuxu lze zobrazit stav a nastavovat nejrůznější parametry, které se nejvíce týkají akcelerace přenosu dat v síťové kartě pomocí nástroje ethtool. Příklad:
$ sudo ethtool enx34d0b8c0b534
Settings for enx34d0b8c0b534:
Supported ports: [ TP MII ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Half 1000baseT/Full
Supported pause frame use: No
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: Symmetric Receive-only
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Link partner advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Link partner advertised pause frame use: Symmetric
Link partner advertised auto-negotiation: Yes
Link partner advertised FEC modes: Not reported
Speed: 1000Mb/s
Duplex: Full
Port: MII
PHYAD: 32
Transceiver: internal
Auto-negotiation: on
Supports Wake-on: pumbg
Wake-on: d
Current message level: 0x00007fff (32767)
drv probe link timer ifdown ifup rx_err tx_err tx_queued intr tx_done rx_status pktdata hw wol
Link detected: yes
$ sudo ethtool -k enx34d0b8c0b534
Features for enx34d0b8c0b534:
rx-checksumming: on
tx-checksumming: on
tx-checksum-ipv4: on
tx-checksum-ip-generic: off [fixed]
tx-checksum-ipv6: on
tx-checksum-fcoe-crc: off [fixed]
tx-checksum-sctp: off [fixed]
scatter-gather: on
tx-scatter-gather: on
tx-scatter-gather-fraglist: on
tcp-segmentation-offload: on
tx-tcp-segmentation: on
tx-tcp-ecn-segmentation: off [fixed]
tx-tcp-mangleid-segmentation: off
tx-tcp6-segmentation: on
udp-fragmentation-offload: off
generic-segmentation-offload: on
generic-receive-offload: on
large-receive-offload: off [fixed]
rx-vlan-offload: on
tx-vlan-offload: on
ntuple-filters: off [fixed]
receive-hashing: off [fixed]
highdma: off [fixed]
rx-vlan-filter: off [fixed]
vlan-challenged: off [fixed]
tx-lockless: off [fixed]
netns-local: off [fixed]
tx-gso-robust: off [fixed]
tx-fcoe-segmentation: off [fixed]
tx-gre-segmentation: off [fixed]
tx-gre-csum-segmentation: off [fixed]
tx-ipxip4-segmentation: off [fixed]
tx-ipxip6-segmentation: off [fixed]
tx-udp_tnl-segmentation: off [fixed]
tx-udp_tnl-csum-segmentation: off [fixed]
tx-gso-partial: off [fixed]
tx-sctp-segmentation: off [fixed]
tx-esp-segmentation: off [fixed]
tx-udp-segmentation: off [fixed]
fcoe-mtu: off [fixed]
tx-nocache-copy: off
loopback: off [fixed]
rx-fcs: off [fixed]
rx-all: off [fixed]
tx-vlan-stag-hw-insert: off [fixed]
rx-vlan-stag-hw-parse: off [fixed]
rx-vlan-stag-filter: off [fixed]
l2-fwd-offload: off [fixed]
hw-tc-offload: off [fixed]
esp-hw-offload: off [fixed]
esp-tx-csum-hw-offload: off [fixed]
rx-udp_tunnel-port-offload: off [fixed]
tls-hw-tx-offload: off [fixed]
tls-hw-rx-offload: off [fixed]
rx-gro-hw: off [fixed]
tls-hw-record: off [fixed]
Protože tato sekce pojednává o skutečné fyzické a linkové vrstvě, je ve virtuálním prostředí význam a obsah výpisů uvedených příkazů omezen. Proto jsou příklady také zachyceny z fyzické síťové karty.
Tyto parametry nás v tomto kurzu tolik zajímat nebudou, přesto jimi začínáme, protože v reálném nasazení na serverech jsou důležité pro vyladění výkonu a případné řešení problémů pod zátěží. Konkrétní použití však silně závisí na konkrétním čipu a ovladači síťového rozhraní a na případu užití.
Ethernet
Ethernet si s sebou nese dlouhou historii z doby, kdy se používal nad fyzickou sdílenou sběrnicí v podobě koaxiálního kabelu. Strukturovaná kabeláž a huby umožnily emulovat sdílenou sběrnici nad kabeláží hvězdicové topologie. Další evolucí došlo k nahrazení hubu - původního centrálního prvku hvězdicové topolgie, switchem. Tím se z jednotlivých propojů mezi síťovými kartami a switchem staly full-duplexní linky, celková propustnost ethernetové sítě se znásobila a odpadla nutnost řídit přístup k médiu metodou CSMA/CD.

Dodnes však Ethernet vytváří segmenty - to co dříve byla jedna sběrnice, může být nyní realizováno množstvím switchů, které jsou spojené do stromové topologie a tvoří souvislou síť, kde mohou stanice mezi sebou volně komunikovat, a kde lze broadcastem oslovit najednou všechny stanice v segmentu.
Hlavní výhodou switchů je, že provádí auto-learning MAC adres, tedy že switch si udržuje tabulku známých MAC adres, kterou postupně vyplňuje ze SRC MAC address políček v etherneových hlavičkách, jak mu přichází provoz od jednotlivých stanic na jednotlivých portech. V okamžiku, kdy má switch doručovat rámec, pokusí se ve své tabulce najít záznam pro DST MAC adresu a pokud ji najde, bude vědět, na jaký port má daný rámec poslat. Pokud záznam nenajde, rozešle rámec na všechny aktivní porty (tomu se říká flooding). Záznamy ve switchovací tabulce se samozřejmě také čistí - dlouho neobnovené záznamy se uklidí po stanovené době. Ta bývá v řádu jednotek minut.
Ethernet, poplatně původní sběrnicové implementaci, předpokládá, že segment má vždy lineární (u sběrnice) nebo stromovou topologii a tedy že neobsahuje žádný kruh. Samo o sobě pro Ethenert znamená zapojení byť jen jediného kruhu mezi dvěma porty switche ve stejném segmentu prakticky okamžité zahlcení celého segmentu v důsledku takzvaného broadcast storm: Jakmile přijde do ethernetového segmentu s kruhem jeden BUM (broadcast nebo unknown unicast) rámec, tedy rámec, který switch rozešle na všechny porty, krom odesílatele, tak se tento rámec přes kruh vrátí do switche, kde je opět rozeslán na všechny porty a tak donekonečna. Kruh tedy funguje jako nekonečný generátor, který opakuje ten samý packet a switch jej rozesílá na všechny porty v daném segmentu.
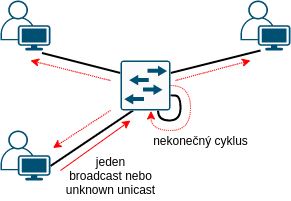
Pochopitelně takto jednoduchá chyba zapojení by neměla vést k zahlcení celé sítě - u hubů a starších switchů tomu tak však opravdu bylo, zapojením kruhové topologie došlo k okamžitému spuštění broadcast storm. Následně vznikl protokol STP (Spanning Tree Protocol), který umožňuje fyzicky zapojit topologii s kruhy a automaticky vypne linky, které by způsobily zakruhování sítě. Tento protokol se masivně užíval k zajištění redundance fyzických propojů, ale má spoustu špatných vlastností, kvůli kterým se od něj ustupuje a to i přesto, že byl několikrát revidován a vznikly novější protokoly RSTP a MSTP i několik proprietárních rozšíření, jako PVST+. K protokolu STP se ještě vrátíme.
Ethernet definuje několik druhů rámců - DIX / Ethernet II je pro nás nejdůležitější, protože to je jediný typ podporovaný linuxovým síťovým stackem. Vedle něj však existuje typ 802.2 LLC, který má využití v konkrétních specifických protokolech. Pro úplnost: Linux dovede komunikovat za specifických podmínek i jinými rámci, než DIX / Ethernet II. Například implementace protokolu STP v linuxovém jádře používá 802.2 LLC a má proto ve zpracování packetů výjimku z pravidla o výhradní podpoře rámců typu Ethernet II.
Odkazy:
VLAN
Dejme tomu, že máme switch se 48 porty a máme dvě oddělené skupiny stanic, které chceme oddělit do dvou izolovaných Ethernetových segmentů. VLAN řeší přesně tento problém - porty pro první skupinu nastavíme jako access porty pro VLAN 1 a porty pro druhou skupinu jako access pro VLAN 2. Co když ale máme server, nebo další switch, který má být členem obou skupin a tedy součástí obou VLAN. Pochopitelně můžeme pro takový server vyčlenit dva access porty pro obě VLANy. Jenže, co když máme VLAN víc?
Na to je potřeba mít možnost přes jeden port a přes jedno fyzické médium odděleně pustit více skupin, tedy umožnit, aby jeden port byl členem více VLAN a označkovat rámce, které se na tomto portu přenáší, číslem VLANy, do které patří. Na tohle existuje několik implementací, nicméně za obecný standard lze považovat 802.1Q.
V Cisco terminologii se portu, který může přenášet rámce z více VLAN, říká trunk. Na této společné lince, vedoucí z trunk portu, se ethernetové rámce značkují pomocí 802.1Q rozšíření ethernetové hlavičky číslem VLAN v rozsahu 1-4094 (12 bitů mínus rezervované hodnoty).
Ethernetová hlavička bez 802.1Q
| Preambule + SFD | Cílová MAC adresa | Zdrojová MAC adresa | Ether Type | Payload (data) | CRC / FCS |
|---|---|---|---|---|---|
| 8 bytů | 6 bytů | 6 bytů | 2 byty | 46 - 1500 bytů | 4 byty |
Ethernetová hlavička bez 802.1Q
| Preambule + SFD | Cílová MAC adresa | Zdrojová MAC adresa | 802.1Q header | Ether Type | Payload (data) | CRC / FCS |
|---|---|---|---|---|---|---|
| 8 bytů | 6 bytů | 6 bytů | 4 bytů | 2 byty | 46 - 1500 bytů | 4 byty |
Na stranu switchů se dá pohlížet buď tak, že pro každou VLANu je fyzický switch rozdělen na pod-switche, které mají do dané VLANy zapojené jen některé (access) porty, které vysílají i přijmají rámce standardně, tedy bez 802.1Q značky. A krom toho mohou mít i sdílené trunk porty, na které musí vysílat rámce s 802.1Q značkou se správně vyplněným číslem VLAN. A do dané VLAN přicházejí z trunk portů jen rámce, co měly příslušné číslo VLAN v 802.1Q značce. Krom toho trunk port může mít jednu VLAN zvolenou jako nativní, tedy pro tuto VLAN se chová jako normální (access) port a vysílá a přijímá v ní rámce bez 802.1Q značky.
Každý takový virtuální switch pracuje v našem myšlenkovém modelu nezávisle - pro svou VLAN si vyplňuje switchovací tabulku podle SRC MAC adres v příchozích rámcích, kde si zaznamenává z jakého portu (včetně trunk portů s abstrakcí VLAN značek) přišla která MAC adresa.
Alternativně můžeme switch s podporou VLAN chápat blíže skutečné implementaci, totiž že switch má ve switchovací tabulce sloupec pro VLAN, který musí odpovídat číslu VLAN asociovanému ke každému rámci. Port pak v režimu access podle své příslušnosti konkrétní VLAN přidává před zpracováním virtuální číslo VLAN všem rámcům, které přes něj přijdou (bez fyzické značky). Trunk porty používají při zpracování rámců v tabulce skutečné hodnoty z 802.1Q značek a stejně tak při vysílání rámců přes trunk port je do 802.1Q značky vyplněno příslušné číslo VLAN. Výjimku představuje nativní VLAN na trunk portu, pro kterou je funkce portu shodná, jako u access portu.
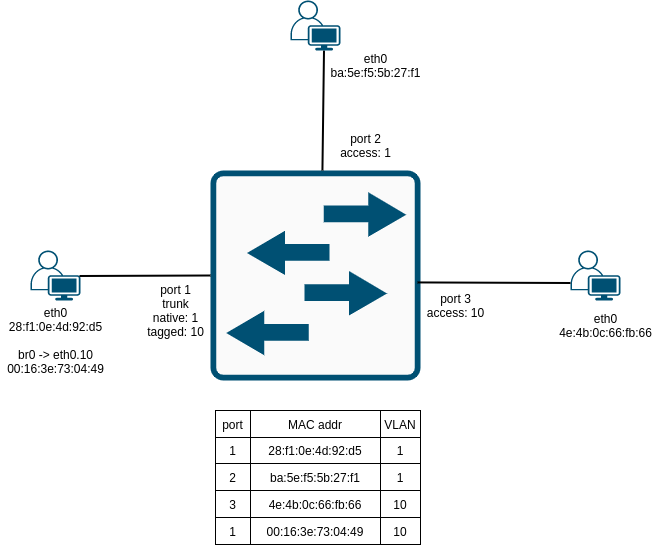
Zopakujme stručně, co se stane, když například na port 1 switche z předchozího obrázku přijde následující rámec:
Ethernetová hlavička bez 802.1Q
| Preambule + SFD | Cílová MAC adresa | Zdrojová MAC adresa | 802.1Q header | Ether Type | Payload (data) | CRC / FCS |
|---|---|---|---|---|---|---|
| konstanta | 4e:4b:0c:66:fb:66 | 00:16:3e:73:04:49 | 0x8100 0x000a | 0x0800 | IP + HTTP | *** |
Switch na předchozím obrázku vykoná následující:
- Ověří, že zdrojová MAC 00:16:3e:73:04:49 je v tabulce asociovaná s portem 1 a VLAN 10 (0x0a v 802.1Q headeru), což v našem případě je. Jinak by tento záznam switch vytvořil.
- Najde výstupní port pro cílovou MAC 4e:4b:0c:66:fb:66 ve VLAN 10 (0x0a), což je v našem případě předposlední záznam ve switch tabulce.
- V našem případě tedy odešle rámec na výstupní port určený předposledním záznamem v tabulce, to je port 3, který je access pro VLAN 10 a proto bude z rámce odebrán 802.1Q header. jinak se rámec nezmění.
- Pokud by v tabulce žádný záznam pro cílovou MAC adresu ve VLAN 10 nebyl, switch by rámec rozeslal na všechny porty, co jsou ve VLAN 10, s výjimkou portu, odkud rámec přišel, tedy portu 1.
- Při odesílání rámce na trunk port do VLANy, která není nativní, switch vyplní 802.1Q header, naopak do access portu a nebo nativní VLAN trunk portu pošle rámec bez 802.1Q tagu a přesně tak očekává, že bude rámce přijímat od protistran.
VLAN a Linux
V Linuxu jsou síťové karty - eth0, nebo třeba enp3s0, obyčejné neotagované porty a můžeme je chápat, jako protistranu access portu switche. Chceme-li Linux připojit k trunk portu, potřebujeme mít možnost přijmat a vysílat rámce s 802.1Q tagem pro konkrétní číslo VLANy. To v Linuxu uděláme pomocí virtuálního síťového rozhraní, které vlastně nadstavbou nad konkrétním fyzickým (nebo případně virtuálním) ethernetovým rozhraním.
Rámce neoznačené 802.1Q značkou (tag) přichází a vstupují do síťového stacku ze síťového interfacu, který odpovídá fyzickému (nebo virtuálnímu) ethernetovému adaptéru. Naopak PDU vyšších vrstev, která se mají zabalit do ethernetového rámce a odeslat přes interface odpovídající fyzickému, odejdou bez 802.1Q značky. Dorazí tedy na straně switche do VLAN určené jako access nebo v případě trunk portu do VLAN označené jako native pro daný trunk port. Následující schéma ukazuje, jak to bude vypadat v našem příkladě s nativní VLAN1 a taggovanou (ne-nativní) VLAN 10:
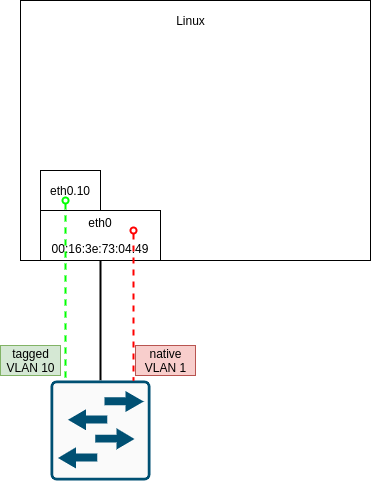
Rámce označené pomocí 802.1Q tagů přijímá linuxové jádro přes fyzické síťové rozhraní a na tomto rozhraní je lze i zachytit pomocí nástroje tcpdump a to včetně 802.1Q tagu. Do síťového stacku však vstoupí z příslušného VLAN rozhraní (eth0.10 v našem příkladě), které musí být vytvořeno nad fyzickým ethernetovým rozhraním, kterým označený rámec přišel. Číslo VLAN nastavené na rozhraní se musí shodovat s 802.1Q tagem. Pokud některá z těchto podmínek neplatí, je daný rámec zahozen a nebude dále zpracován.
Pro odesílaní rámců přes VLAN rozhraní platí podobná pravidla. Hierarchické pojmenování - v příkladě eth0.10 je jen konvence. (Na starších jádrech to bylo jedno ze čtyř povolených pojmenování VLAN interfacu. Na nových jádrech - 4.0+ se už ale síťové interfacy mohou jmenovat jakkoliv. Přesto je dobrý zvyk číslo VLAN ve jménu interfacu zachovat.) Podrobněji se podíváme na nastavení VLAN interfaců v další kapitole.
L3 - IPv4 a IPv6
Jak už bylo vysvětleno v předchozí kapitole, protokoly třetí vrstvy zajišťují:
- globální adresování
- routing
IP adresy
Protokoly IPv4 i IPv6 mají společné to, že pro adresování stanic používají IP adresy. U IPv4 jsou dlouhé 32 bitů a v protokolu IPv6 jsou 128 bitů dlouhé.
Pro adresování sítí (subnetů) se používá u obou protokolů kombinace adresy sítě („nulté“ IP adresy v daném subnetu) a síťové masky, která se zapisuje jako počet bitů v adrese (počítají se souvisle zleva), které patří adrese sítě a zbytek je adresa stanice v rámci subnetu. U IPv4 i IPv6 se tedy používá zápis s lomítkem, například:
- 192.168.1.0/24
- 2001:db8:1::/64
Mimo to se ještě občas vidí u IPv4 použití zápisu s (explicitní) síťovou maskou, např. místo 192.168.1.0/24 to je 192.168.1.0/255.255.255.0. Tohle je však historická specialita IPv4 a u IPv6 není možná - jediný přípustný zápis IPv6 adresy je s délkou masky v bitech.
Na IP adresy se v případě obou protokolů často díváme jako na řetězce 32 respektive 128 bitů. U IPv4 to je skoro přirozené, protože na 32-bitových počítačích nám 32 bitů IP adresy krásně zapadá do unsigned integeru a dá se proto snadno uložit a zpracovávat. U IPv6 je nejužitečnější představit si adresu jako 128 bitů v jedné proměnné (i když ve skutečnosti to bývá datová struktura se čtyřmi 32-bitovými čísly a nebo pole 16ti bytů).
IPv4 adresy se obvykle zapisují dekadicky po osmi bitech oddělených tečkami. Zato zápis IPv6 adres je poněkud komplikovaný, nicméně to má svoje důvody. Nebudu zabíhat do detailů, raději odkážu podrobné vysvětlení např. z Wikipedie. Pro nás stačí vědět, že existuje kanonický zápis, kde jsou explicitně uvedena všechna čísla (nibly). Adresa se zapisuje hexadecimálně po 16ti bytech oddělených dvojtečkou. Naproti tomu existují různá pravidla, jak lze adresu zkrátit, zejména vynecháváním nulových niblů a vynecháváním celých sekcí s nulami. Například tyto dvě adresy jsou synonyma:
- 2001:0db8:85a3:0000:0000:8a2e:0370:7334
- 2001:db8:85a3::8a2e:370:7334
Samotná číselná hodnota adresy je sice bezrozměrný řetězec bitů, přesto ale existují skupiny nebo typy adres. U IPv4 to jsou adresy zakázané nebo nepoužitelné (0.0.0.0 a nebo adresy loopbacků ze subnetu 127.0.0.0/8). Pak to jsou adresy vyčleněné pro použití v lokálních sítích, které se nesmí používat v Internetu (privátní adresy dle RFC 1918, tedy například subnety 10.0.0.0/8 nebo 192.168.0.0/16). Dále máme normálně použitelné unicast adresy, adresy multicastových skupin a link-local adresy, které známe z (pro IPv4 né moc užitečné autokonfigurace).
U IPv6 jsou naopak linkové (link-local) adresy nesmírně užitečné a všudypřítomné. Navíc IPv6 přineslo ULA adresy a o trochu komplikovanější členění multicast adres.
Odkazy:
Routing
Routing vychází ze schopnosti snadno určit, do kterého subnetu z možných kandidátů patří konkrétní adresa. Protokoly IP (v4 i v6) totiž používají směrovací tabulku, která je vytvořena ruční nebo automatickou konfigurací na každém počítači / zařízení, které podporuje protokol IP. Pro IPv4 může tabulka vypadat například takto:
| target | next-hop | destination device |
|---|---|---|
| 0.0.0.0/0 | 192.168.0.1 | enp0s3 |
| 10.0.3.0/24 | lxcbr0 | |
| 192.168.0.0/24 | enp0s3 | |
| 192.168.0.1/32 | enp0s3 |
Ve skutečnosti jsme tu jen přepsali do přehlednější tabulky skutečnou směrovací tabulku z našeho experimentálního prostředí:
root@osboxes:/home/osboxes# ip route
default via 192.168.0.1 dev enp0s3 proto dhcp src 192.168.0.100 metric 100
10.0.3.0/24 dev lxcbr0 proto kernel scope link src 10.0.3.1
192.168.0.0/24 dev enp0s3 proto kernel scope link src 192.168.0.100
192.168.0.1 dev enp0s3 proto dhcp scope link src 192.168.0.100 metric 100
První sloupec vyznačuje target, tedy subnet do kterého díky tomuto řádku známe cestu. Následuje buď via NEXT-HOP nebo jen dev DEVICE. To jsou dva základní druhy záznamů - pokud má záznam via NEXT-HOP, znamená to, že to je záznam co vede na další router - ten je určen adresou NEXT-HOP a eventuálně síťovým rozhraním DEVICE, která usnadňuje výběr.
Naproti tomu záznam bez via NEXT-HOP jen s dev DEVICE je takzvaná connected route a říká, že daný subnet je dostupný lokálně po L2, protože síťové rozhraní DEVICE má přímý přístup do L2 segmentu, kde je lokálně aspoň jedna adresa z daného subnetu nastavena. Ostatní adresy z tohoto subnetu jsou pak dostupné tímto interfacem přes L2. To znamená, že v závislosti na tom, jaká technologie je dané síťové rozhraní, lze přes ní komunikovat s ostatními IP adresami v daném subnetu. V případě Ethernetu je na to potřeba protokol na překlad IP adres na MAC adresy: ARP pro IPv4 a NDP pro IPv6.
Dejme tomu, že tedy chceme doručit IP datagram:
| IP verze | (další pole) | Cílová IP adresa | Zdrojová IP adresa | Payload (data) | |||||
|---|---|---|---|---|---|---|---|---|---|
| 4 | * | 192.168.0.242 | 192.168.0.100 | TCP/UDP/... |
Směrovací rozhodnutí se řídí pouze cílovou adresou. Je tedy třeba zjistit, který záznam ve směrovací tabulce se má pro směrování datagramu s cílovou adresou 192.168.0.242 použít. Na to IP používá Longest Prefix Match (LPM). Pro každý záznam ve směrovací tabulce se vypočte bitový AND cílové adresy a síťové masky (nyní se díváme na adresu i na síťovou masku jako na řetězec bitů odpovídající délky):
- 0.0.0.0/0: 192.168.0.242 AND 0.0.0.0 = 0.0.0.0, záznam tedy odpovídá výsledku a délka matche je 0
- 10.0.3.0/24: 192.168.0.242 AND 255.255.255.0 = 192.168.0.0, záznam tedy neodpovídá
- 192.168.0.0/24: 192.168.0.242 AND 255.255.255.0 = 192.168.0.0, záznam odpovídá výsledku a délka matche je 24
- 192.168.0.1/32: 192.168.0.242 AND 255.255.255.255 = 192.168.0.242, záznam neodpovídá
Ze směrovací tabulky tedy odpovídají dva záznamy - první a třetí. Delší masku (24>0) má třetí záznam a proto se dle LPM použije k odeslání rámce třetí záznam. To je connected route, která říká, že celý subnet 192.168.0.0/24 je dostupný přes L2 přes rozhraní enp0s3. Tuhle úvahu si můžeme ověřit na našem pokusném scénáři:
root@osboxes:/home/osboxes# ip route get 192.168.0.242
192.168.0.242 dev enp0s3 src 192.168.0.100 uid 0 cache
IP datagram je tedy předán nižší vrstvě, která však potřebuje znát MAC adresu interfacu, na kterém je nastavena cílová adresa 192.168.0.242. Protokol ARP si udržuje cache známých dvojic IP - MAC. Pokud v cache nenajde záznam pro 192.168.0.242, pošle ethernetovým broadcastem ARP výzvu, aby se stanice s adresou 192.168.0.242 ohlásila. Jakmile dostane odpověď, může si vyplnit příslušný záznam do ARP cache a doplnění MAC headeru a odeslání původního IP datagramu přes Ethernet už nic nebrání. Takhle vypadá v mém případě ARP cache:
root@osboxes:/home/osboxes# ip neighbor
...
192.168.0.242 dev enp0s3 lladdr 28:f1:0e:4d:92:d5 REACHABLE
V případě, že bychom chtěli poslat datagram například na adresu 8.8.8.8, tak bude průběh obdobný - jediný záznam v route tabulce, který bude tentokrát matchovat, bude pouze první záznam (default route). Ten má jako cíl next-hop 192.168.0.1. ARPem se tedy nebude vyhledávat cílová adresa v IP datagramu, nýbrž adresa next-hopu 192.168.0.1.
root@osboxes:/home/osboxes# ip route get 8.8.8.8
8.8.8.8 via 192.168.0.1 dev enp0s3 src 192.168.0.100 uid 0 cache
ARP a NDP
Funkci protokolu ARP jsme vysvětlili v podstatě dostatečně už o dva odstavce výše tím, že v okamžiku odesílání IP datagramu přes multi-access L2, tedy například přes Ethernet, potřebujeme znát L2 adresu, která odpovídá IP adrese, o které víme, že je dostupná přímo přes danou L2 konektivitu.
ARP je protokol velmi jednoduchý - potřebujeme znát MAC adresu pro danou IP adresu a tak se zkrátka zeptáme všech stanic v daném ethernetovém segmentu broadcastem. Stanice, která danou adresu má, nám odpoví (unicastem). ARP dotazy i odpovědi se posílají přímo v ethernetových rámcích.
Záznamy v ARP cache mají omezenou životnost a po jejím vypršení se záznam smaže. Pokud bude po smazání záznam znovu zapotřebí, tak se musíme zeptat znovu ARP dotazem. Doba životnosti záznamů se dá zpravidla nastavit, nicméně default hodnota se hodně liší na různých operačních systémech. V Linuxu to je maličko složitější, protože Linux se snaží minimalizovat počet zbytečných ARP dotazů a zároveň pružně reagovat na situaci, kdy informace v ARP cache přestane být pravdivá. Detaily jsou popsány v https://man7.org/linux/man-pages/man7/arp.7.html. S jistou mírou zjednodušení se dá ale říct, že v Linuxu bude životnost neplatného záznamu v řadu několika minut.
Naproti tomu Cisco IOS a i novější Cisco systémy mají ARP timeout v řádu hodin. To může být někdy překvapení, pokud založíme strategii migrace IP adres z jednoho serveru na jiný na předpokladu, že ARP záznamy vyprší za pár minut a najednou to není pravda. Má to řešení v podobě rozeslání „nevyžádané“ ARP odpovědi - gratuitous ARP.
Pro IPv6 byl vytvořen zcela nový protokol NDP, který je svojí funkcí podobný, avšak je mnohem elegantnější. NDP dotazy se nerozesílají pouhým broadcastem jako payloady ethernetových rámců. Místo toho je NDP jen typem zpráv protokolu ICMPv6 a místo ethernetového broadcastu se posílají NDP requesty IPv6 multicastem. Na první pohled to vypadá složitě, nicméně je to mnohem elegantnější, než ARP, protože IPv6 zavádí linkové adresy - IPv6 adresy odvozené od MAC adresy pomocí prefixu fe80::/64 a mechanismu EUI-64 (spodních 64 bitů IPv6 adresy se na ethernetovém rozhraní odvodí z jeho ze 48-bitové MAC adresy a přidá se konstantní padding ff:fe). Tuto linkovou adresu má interface jakmile se zapne a tato adresa je z definice unikátní v rámci ethernetového segmentu, protože MAC adresa musí být unikátní. Když by náhodou došlo ke kolizi MAC adres v ethernetovém segmentu, nebude fungovat pro kolidující stanice nejen protokol NDP, ale ani ARP a vlastně skoro nic v obou protokolech IP. O multicastu se teď nebudeme rozepisovat, ale je dobré o něm vědět, že uzel sítě může být členem mnoha multicastových skupin. Ke členství se musí přihlásit (protokolem IGMP pro IPv4 resp. MLD pro IPv6) a switche v dané síti mohou přihlašování do skupin využívat k optimalizaci multicastového trafficu, tedy že neposílají multicastové rámce na porty, kde není přihlášen odběr dané skupiny. V případě, že switche IGMP resp. MLD neakceptují, tak se k multicastu chovají, jako by to byl broadcast. Pro NDP se používá ještě trik navíc: NDP nemá jednu konkrétní multicastovou adresu (skupinu), kterou by oslovovala všechny stanice v síti, ale používá takzvanou Solicited-node multicast address, kdy se do multicastové adresy z prefixu ff02::1:ff00:0/104 zakóduje část adresy, na kterou se dotazujeme. Tím se dá ještě urychlit zpracování dotazů na straně stanic, které dotaz dostanou, ale nejsou adresátem. Pro detaily přidávám odkazy na relevantní stránky na Wikipedii. Bohužel, mnohé z nich nemají české heslo a tak nezbývá, než Wikipedie anglická.
Odkazy:
- https://wiki.wireshark.org/Gratuitous_ARP
- https://en.wikipedia.org/wiki/Address_Resolution_Protocol
- https://cs.wikipedia.org/wiki/ICMPv6
- https://cs.wikipedia.org/wiki/Internet_Group_Management_Protocol
- https://en.wikipedia.org/wiki/Multicast_Listener_Discovery
- https://en.wikipedia.org/wiki/Solicited-node_multicast_address
Routing v Internetu
Jak funguje routing v Internetu jsme už vlastně naznačili v předchozí kapitole. Pro jistotu si ale ještě projdeme následující příklad:
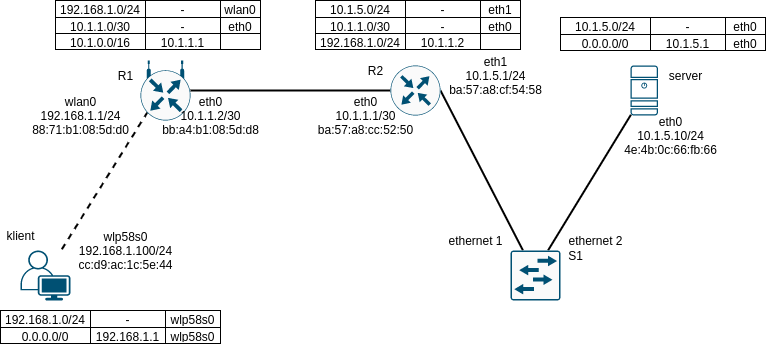
Dejme tomu, že uživatel vlevo dole chce poslat HTTP request na adresu 10.1.5.10. Že takovému HTTP requestu předchází zpravidla DNS dotaz a odpověď teď zatím zanedbáme. HTTP je protokol sedmé vrstvy a přenáší se přes TCP. TCP musí sestavit spojení, tedy poslat trojici TCP segmentů (dva z klienta na server a jeden ze serveru na klienta), kterou udělá „handshake“. TCP se přenáší v IP, v našem příkladě v IPv4 (i když v IPv6 by to bylo skoro totožné). Rozebereme si, jak tedy protokol IP doručí první dva TCP segmenty - jeden od klienta na server a druhý v opačném směru. První datagram bude:
| IP verze | (další pole) | Cílová IP adresa | Zdrojová IP adresa | Payload (data) |
|---|---|---|---|---|
| 4 | * | 10.1.5.10 | ? | TCP, dport 80 |
Klient musí vybrat záznam ve směrovací tabulce, který použije k odeslání IP datagramu. Jediný záznam, který matchuje, je default route (0.0.0.0/0), který vede na next-hop 192.168.1.1 přes interface wlp58s0. Tato informace klientovi stačí, aby zkusil najít v ARP cache záznam pro IP adresu 192.168.1.1 a s jeho pomocí mohl vyplnit cílovou adresu v L2 hlavičce. Mezi klientem a routerem R1 je sice WiFi, ale ta se v této situaci chová obdobně jako Ethernet (a rozebereme si to později detailně). Pokud klient L2 (MAC) adresu v ARP cache nenajde, vyvolá ARP dotaz, aby zjistil, kam datagram poslat. V našem příkladě bude výsledek 88:71:b1:08:5d:d0.
Klient musí při navazování spojení rozhodnout nejen, kterým rozhraním odešle první TCP segment, ale i jakou IP adresu použije jako zdrojovou. V našem případě je to však jednoduché - jediné rozhraní, které klient má (krom loopbacku), a přes které tedy bude první datagram odcházet, je WiFi karta wlp58s0. Z tohoto rozhraní tedy klient použije zdrojovou IP adresu 192.168.1.100 a i zdrojovou MAC adresu cc:d9:ac:1c:5e:44 - tohle rozhodnutí udělá jen na začátku, pak už je TCP spojení určeno neměnnou čtveřicí: zdrojová a cílová IP adresa a zdrojový a cílový port.
V našem případě tedy přes WiFi rozhraní wlp58s0 odejde následující rámec. Pro jednoduchost se nebudeme zabývat specialitami WiFi a představíme si, že WiFi emuluje Ethernet, což je do znační míry pravda:
| Cílová MAC adresa | Zdrojová MAC adr. | Ether Type | IP verze | (další pole) | Cílová IP adr. | Zdrojová IP adr. | Payload (data) |
|---|---|---|---|---|---|---|---|
| 88:71:b1:08:5d:d0 | cc:d9:ac:1c:5e:44 | 0x0800 | 4 | * | 10.1.5.10 | 192.168.1.100 | TCP, dport 80 |
Předpokládejme, že datagram úspěšné dorazil na router R1 po L2 mezi klientem a R1. R1 datagram vybalí z MAC hlavičky (při tom se kontroluje, že cílová MAC adresa rámce je adresa rozhraní wlan0 na R1). Kdyby nebyla, rámec by se zahodil.
Router R1 vyhledá podle pravidla LPM nejlepší cestu pro cílovou adresu z datagramu 10.1.5.10. Ve směrovací tabulce R1 je nejlepší (a jediný) match poslední cesta
10.1.0.0/16 via 10.1.1.1. Tato informace nám však nestačí, protože nevíme, přes které rozhraní máme datagram poslat. Proto je třeba udělat rekurzivní vyhledání next-hopu 10.1.1.1 z výsledku vyhledání cílové adresy z datagramu. Pro adresu 10.1.1.1 matchuje záznam10.1.1.0/30 dev eth0. To je connected route a říká nám tedy, že next-hop pro datagram je dostupný přes L2, rozhraní eth0. Udělá se tedy opět ARP vyhledání resp. ARP request + reply transakce, aby se zjistila cílová MAC adresa pro 10.1.1.1 přes eth0 a po Ethernetu mezi R1 a R2 odejde rámec takhto:
| Cílová MAC adresa | Zdrojová MAC adr. | Ether Type | IP verze | (další pole) | Cílová IP adr. | Zdrojová IP adr. | Payload (data) |
|---|---|---|---|---|---|---|---|
| ba:57:a8:cc:52:50 | bb:a4:b1:08:5d:d8 | 0x0800 | 4 | * | 10.1.5.10 | 192.168.1.100 | TCP, dport 80 |
IP adresy v hlavičce se ovšem nijak nezměnily - ty zůstávají po celý přenos stejné, v IP hlavičce se jen odečítá pole TTL na každém routeru, ale jinak všechny změny probíhají v MAC hlavičce. Mimochodem, TTL pole (v našem příkladě není explicitně vypsané, ale spadalo by do sekce „další pole“) slouží k prevenci smyček: při každém průchodu routerem se odečte z inicializované hodnoty (zpravidla 64) jednička. Jakmile by se hodnota snížila na nulu (tedy po průchodu 64 routery, což značí, že se pravděpodobně zasmyčkoval), bude datagram zahozen.
- Na routeru R2 se situace opakuje - IP datagram je vybalen z ethernetové hlavičky, vyhledá se nejlepší záznam podle LPM, což je záznam
10.1.5.0/24 dev eth1, což je connected route a tedy router R2 vyhledá pomocí ARPu MAC adresu pro cílovou adresu 10.1.5.10 z našeho datagramu. MAC adresa bude 4e:4b:0c:66:fb:66 a datagram se tak může doručit přes L2 k cíli v této formě:
| Cílová MAC adresa | Zdrojová MAC adr. | Ether Type | IP verze | (další pole) | Cílová IP adr. | Zdrojová IP adr. | Payload (data) |
|---|---|---|---|---|---|---|---|
| 4e:4b:0c:66:fb:66 | ba:57:a8:cf:54:58 | 0x0800 | 4 | * | 10.1.5.10 | 192.168.1.100 | TCP, dport 80 |
V cestě nám ještě stojí switch S1, ale ten do IP hlavičky nekouká vůbec a v ethernetové hlavičce nic nemění. Pouze si z procházejícího datagramu zapamatuje do switchovací tabulky, že MAC adresa ba:57:a8:cf:54:58 je dostupná na portu ethernet 1. Pokud bude mít ve switchovací tabulce informaci o tom, na kterém portu je MAC adresa 4e:4b:0c:66:fb:66 (je na portu ethernet 2), odešle náš rámec jen na tento port. Jinak jej rozešle na všechny aktivní porty (v dané VLAN, což už tu pro jednoduchost detailně znovu nerozebíráme).
Jakmile rámec dorazí na rozhraní eth0 serveru a následně je předán prokolu IP, zjistí se porovnání cílové adresy s adresou rozhraní, že server je adresátem datagramu a datagram je předán vyšším vrstvám TCP/IP stacku ke zpracování.
Odpověď od serveru ke klientovi bude doručovaná obdobně, jen v opačném směru, neboť odpověď bude mít v prvotním IP datagramu naopak cílovou a zdrojovou adresu, než měl původní dotaz, který jsme v minulém odstavci rozebrali.
ICMP
Protokol ICMP slouží k signalizaci o chybách, provozních událostech protokolu IP (IPv4 i IPv6) i protokolů vyšších vrstev, přičemž tato signalizace má v mnoha situacích přímý dopad na provoz, kterého se ICMP zprávy týkají. Vedle toho protokol ICMP přináší nejznámější nástroj na řešení problémů - ICMP echo request a echo reply zprávy, známé též jako ping. Pro IPv6 implementuje protokol IPv6 mechanismus na zjištění L2 adresy pro IP adresu na multi-access síti - protokol NDP, který nahrazuje pro IPv6 protokol ARP z IPv4. Dále ICMPv6 přineslo robustní mechanismus autokonfigurace pro IPv6 - SLAAC a mechanismus detekce duplicitních adres (DAD) pomocí NDP.
ICMP datagramy se přenášení jako payload (data) v IP, tedy původní ICMP v IPv4 a ICMPv6 v IPv6. V tomto okamžiku je nejvyšší čas na varování: ICMP je užitečný protokol, bez kterého protokol IP bude fungovat suboptimálně a nebo v některých situacích nebude fungovat vůbec. Pokud tedy nastavujete firewall a nebo se setkáte s nastavením firewallu, které omezuje ICMP, je třeba zbystřit a dobře si rozmyslet implikace.
První upozornění je, že když spolu komunikují dvě IP adresy, například 192.168.1.100 a 10.1.5.10, tak přesto v souvislosti s touto komunikací může libovolný router po cestě poslat ICMP zprávu jednomu z komunikujícího páru. Taková ICMP zpráva tedy přichází z předem neznámé a neočekávané IP adresy - řekněme 10.1.1.2 , abychom se vrátili k předchozímu případu. Přesto taková zpráva může být relevantní a někdy i kritická pro správné fungování protokolu IP.
Odkazy:
Path MTU discovery
ICMP hraje takto kritickou roli v mechanismu Path MTU discovery. Musíme se ještě zmínit o jedné věci, která dosud nepadla: každá L2 technologie zavádí specifické omezení na maximální délku rámce (Maximum Transmission Unit - MTU). Ta je pro Ethernet obvykle 1500B, ale na různých sítích může být vyšší i nižší. Příklad, kde je obvykle nižší, jsou VDSL linky, které jsou nad DSL vrstvou zpravidla emulovaný Ethernet a nad ním se provozuje protokol PPPoE, jehož MTU je 1500 (Ethenet) - 8 bytů na overhead PPPoE, tedy 1492 B. Další příklad je tunel IP v IP, kde je overhead 20 B na IP header, takže MTU je pak 1480.
Bez ohledu na příčinu menšího MTU, protokol IP se musí umět vyrovnat se situací, kdy klient odešle IP datagram délky rovné MTU jeho síťového rozhraní, dejme tomu 1500B a tento datagram narazí cestou na linku, která má menší MTU, než je jeho délka. Protokol IPv4 tuto situaci umí řešit dvěma způsoby:
Fragmentací, tedy že router, kde dochází k redukci MTU cesty, datagram rozdělí na dva a to více-méně useknutím konce, který se už nevejde do MTU, nastavením příslušných flagů v IP hlavičce, které signalizují, že bude následovat zbytek a následně vygenerování, druhého datagramu s novou hlavičkou (docela podobné té původní, jen s nastaveným offsetem na délku prvního fragmentu). Takto rozfragmentovaný datagram dojde až na cílovou stanici, která oba fragmenty spojí a získá tak původní payload. Má to ovšem řadu nevýhod: Samotná fragmentace je docela složitá akce, která se těžko implementuje v hardwaru (a většina velkokapacitních routerů dnes dělá všechnu práci ve specializovaných chipech). Navíc k fragmentaci může cestou dojít víckrát opakovaně, pokud je cestou několik zmenšení MTU za sebou. Tím se může overhead (každý fragment přidává 20B na IP hlavičku) zvýšit do astronomických procent. Navíc jeden z fragmentů se může ztratit a pro koncového hosta je to nepříjemná situace - musí držet došlé fragmenty v paměti, dokud nedojdou ostatní a nebo dokud to nevzdá a datagram nezahodí.
Druhá varianta je datagram, co se nevejde do MTU prostě zahodit. To samo o sobě není moc konstruktivní, jenže o zahození datagramu vygeneruje router, který jej zahodil, ICMP zprávu a pošle jí odesílateli zahozeného datagramu. Ten se z ní dozví, který datagram byl zahozen (do zprávy o zahození se kopíruje hlavička zahozeného datagramu) a dále se dozví, jaké MTU následuje v cestě. Je tedy na odesílateli, aby data, která chce poslat přeorganizoval a poslal náhradou za zahozený datagram nový, ale menší.
Tento krok se může opakovat, pokud je po cestě více zmenšení MTU. Odesílatel musí v každém kroku správně rozpoznat, který datagram byl zahozen a musí si zapamatovat, jaké je pro daný cíl Path MTU. V Linuxu na to slouží route cache. Primárním předpokladem však je, že musí odesílateli zahozeného datagramu dojít ICMP zpráva o zahození - ICMP Fragmentation Needed (Type 3, Code 4).
To, jestli router použije fragmentaci a nebo zahození a vygenerování ICMP zprávy závisí u IPv4 na flagu don't fragment - DF. V současné době velké množství systémů a aplikací nastavuje DF=1, protože fragmentace se považuje za neefektivní a PMTU Discovery by mělo univerzálně fungovat.
Co se ale stane, když příliš horlivý admin někde cestou zakázal ICMP a zprávy o zahození (Fragmentation Needed) se budou zahazovat? Jedná se o naprosto typický projev, nicméně bez prozkoumání situace pomocí nástroje tcpdump se zpravidla neobejdeme. Dejme tomu, že v příkladě z minulé sekce bude klient opět navazovat TCP session na server, dejme tomu, že to bude HTTP request, kterým si vyžádá soubor velký 1MB a předpokládejme, že klient i server budou nastavovat do IP hlaviček DF=1. A představme si, že linka mezi R1 a R2 má z nějakého důvodu MTU 1480 B, a že router R2 neposílá resp. zahazuje všechny ICMP zprávy.
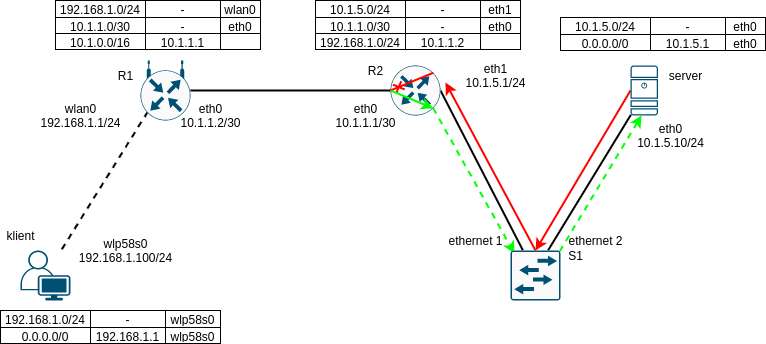
Na začátku každého TCP spojení probíhá 3-way handshake (https://en.wikipedia.org/wiki/Transmission_Control_Protocol#Connection_establishment). Ten se skládá ze 2 TCP segmentů, které jdou ve směru od klienta na server a jednoho potvrzení ze serveru ke klientovi. To jsou všechno malé datagramy dlouhé několik desítek bytů a proto skoro zaručeně projdou (protokol IPv4 vyžaduje minimální MTU 68 B, nicméně většina běžných L2 se pohybuje nad 1000 B, IPv6 pak vyźaduje minimální MTU 1280 B). Jenže jakmile se spojení naváže a klient pošle HTTP dotaz (opět pár desítek, maximálně pár stovek bytů), server se z pohledu klienta odmlčí. Naopak z pohledu serveru server pošle první 1500 B dlouhý IP datagram s daty souboru, který byl vyžádán a nedostane od klienta potvrzení, takže několikát opakuje pokus poslání prvního segmentu, až vyprší timeout a server spojení ukončí.
Celý problém je pochopitelně v tom, že router R2 zahazuje IP datagramy dlouhé 1500 B (červená šipka ve schématu), protože překračují MTU 1480 B a nevysílá resp. zahazuje o tom hlášení protokolem ICMP (zelená šipka ve schématu), které by měl poslat odesílateli zahozených datagramů - serveru. Server tedy neví, v čem je problém a nemůže tedy přizpůsobit odesílané TCP segmenty velikosti MTU po cestě a spojení se proto po slibném začátku rozpadne, jakmile do něj začnou proudit data.
V protokolu IPv6 fragmentace vůbec není definována a proto se všechny datagramy, které překračují MTU zahazují a není tedy jiné cesty, než mít zaručeně funkční Path MTU Discovery.
Odkazy:
Destination unreachable
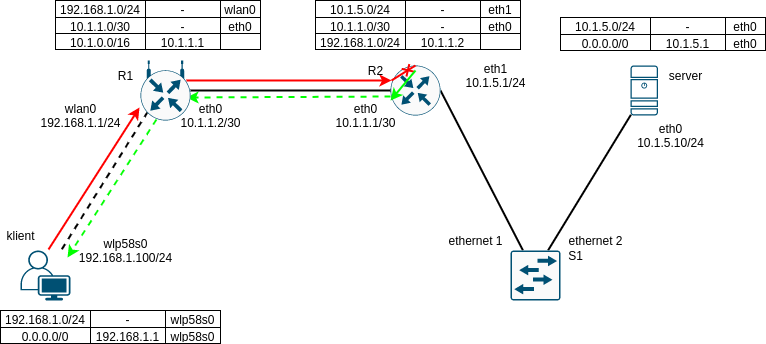
Další nepříjemností pro uživatele sítě, které postihne příliš horlivý admin zakazující ICMP je, že se nedozví o chybách, které nastávají, když se pokouší navázat spojení, resp. obecně komunikovat s různými protistranami. Pokud například klient pokusí navázat TCP spojení na IP adresu, která je v subnetu, na který nevede žádná cesta ve směrovací tabulce, tak první router, který zjistí, že neví, co má s prvním datagramem daného spojení (červená šipka ve schématu níže) dělat, daný datagram zahodí a pošle o tom odesílateli ICMP zprávu (Destination Unreachable - no route to destination) - ta je reprezentována zelenou šipkou.
Pokud ICMP zpráva dorazí odesílateli zahozeného datagramu, je hned jasné, že snaha o spojení je marná, a že jí nemá smysl ani opakovat, ani čekat na odpověď od serveru, na který se připojujeme. Jinými slovy, pokus o spojení z aplikace může být rovnou ukončen a chybové hlášení, které aplikace a snad i uživatel dostane, říká, jaký byl důvod, že spojení selhalo.
Když naopak ICMP zpráva nepřijde, protože je ICMP zahazováno firewallem našeho horlivého admina, tak klient se opakovaně pokouší spojení navázat a čeká na dlouhý timeout (v Linuxu to je v defaultním nastavení TCP stacku 6 pokusů a dohromady přes 2 minuty času). A nakonec aplikace dostane zcela nevypovídající hlášení: Timeout exceeded. O důvodu pak může uživatel jen spekulovat.
Obdobná situace nastává, pokud se klient pokouší komunikovat s adresou, která je sice součástí existující sítě, ale žádný počítač neodpoví routeru, který má do daného subnetu connected route na ARP / NDP (to pak vede na Destination Unreachable - destination host unreachable). Nebo pokud se aplikace pokouší komunikovat protokolem UDP na port, který je zavřený (nikdo na něm neposlouchá). (V případě TCP server reaguje na pokus o navázání TCP spojení na zavřený port segmentem s flagem RST=1.)
TTL Exceeded
Už jsme se zmiňovali o tom, že v IP hlavičce je pole TTL, které se při odeslání datagramu nastavuje na výchozí hodnotu v rozsahu 1-255 (v Linuxu je to 64). Při průchodu každým L3 routerem se odečte od hodnoty TTL jednička a pokud hodnota TTL dosáhne nuly, tak bude datagram zahozen. O tomto zahození se opět vygeneruje ICMP zpráva (Time Exceeded). Její nedoručení má podobné následky, jako zahazování Destination Unreachable zpráv, až na to, že navíc dochází ke zbytečnému zahlcování sítě. Zprávy Time Exceeded jsou totiž zpravidla indikátorem pro to, že je v síti směrovací smyčka.
Nebudeme teď dopodrobna rozebírat, jak taková směrovací smyčka vznikne - člověk jí udělá snadno chybnou ruční konfigurací, jak naznačuje následující schema, kde je červeně zacyklený datagram. Nakonec ho po cca 30ti okruzích jeden z routerů zahodí a měl by o tom vygenerovat ICMP zprávu (zeleně) odesílateli.
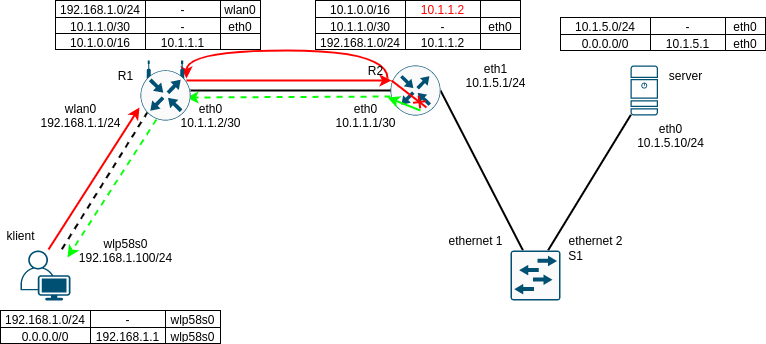
Odkazy:
L4 - TCP, UDP a přehled dalších L4 protokolů
Protokoly vyšších vrstev teď nebudeme dopodrobna rozebírat. Spíš stojí za to říct, co všechno se dá přenášet protokolem IP. Tento přehled bychom mohli snadno odbýt radou: cat /etc/protocols. Tento soubor obsahuje převodní tabulku čísel protokolů, jak se vyskytují v poli Protocol v IPv4 hlavičce resp. poli Next Header u IPv6.
V této tabulce jsou přirozeně dva nejdůležitější zástupci L4 - protkoly TCP (6) a UDP (17). Vedle toho tam ale vidíme i několik typů rozšiřujících hlaviček pro IPv6, protože IPv6 vskutku vrství rozšiřující hlavičky pomocí Next Header pole. A pak také samotné IPv4 (0 a 94) a IPv6 (41). Takto se totiž dělají statické nešifrované tunely - zkrátka se protokolem IP přenáší další hlavička IP a následující payload, ať je to cokoli. IP ve vnitřní i vnější hlavičce může být jak IPv4, tak IPv6, čímž nám vznikají 4 možnosti tunelů - a Linux podporuje všechny 4.
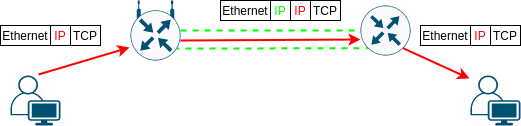
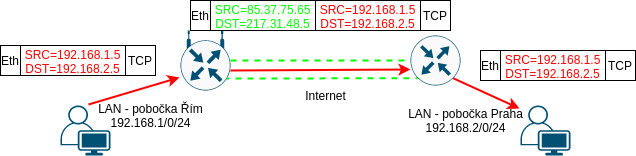
K čemu vlastně tunely jsou? Když zůstaneme u tunelů, které tunelovaný provoz nešifrují, ani nezajištují jeho neměnnost a autenticitu (jako to dělá například IPsec pomocí ESP a AH headerů), tak je smysl tunelů především v oddělení provozu a oddělení adresních prostorů. Typický příklad je, že vnitřní IP header používá adresy, které nelze přenášet přes Internet - například privátní adresy (RFC1918).
Dále možná poznáváte z tabulky v /etc/protocols podle jména GRE - Generic Routing Encapsulation, což je další možnost, jak tunelovat libovolný protokol přes IP - tentokrát se však mezi vnější IP hlavičku a vnitřní (tunelovanou) L3 hlavičku vkládá ještě GRE header. Ten umožňuje mít více tunelů stejného typu mezi jednou dvojicí IP adres identifikující koncové body tunelu. A také umožňuje v jednom tunelu přenášet různé protokoly, zatímco v případě prostého IP-in-IP se musí IPv4-in-IPv4 a IPv6-in-IPv4 (SIT) konfigurovat jako dva zvláštní tunely. Naopak cenou za flexibilitu je vyšší overhead - GRE header má 8 bytů, což nevypadá jako mnoho, ale přidává se to ke každému datagramu, který přes tunel prochází, bez ohledu na jeho velikost. Takže těchto 8 bytů může být pro malý datagram, který přenáší pár bytů užitečného payloadu docela velké procento celkové velikosti.
Další zajímavé protokoly, které lze přenášet přes IP, jsou OSPF - to je link-state směrovací protokol, který impmenetuje například BIRD nebo Quagga. Nebo VRRP - protokol pro volbu mastera ze dvou (nebo více) kandidátů pro zajištění redundance služeb, které daná adresa poskytuje. VRRP je implementován například programem keepalived.
Z hlediska Linuxu je TCP a UDP často poslední protokol TCP/IP stacku, který je implementován v jádře. Vyšší vrstvy, například SSL, jsou pak už implementované jako knihovny v userspace.
Nicméně z hlediska objemu provozu jsou nejdůležitější protokoly, přenášené v IP TCP a UDP. K TCP a UDP přistupují aplikace a knihovny přes tradiční API, známé jako BSD sockets nebo Berkeley sockets. Rozhraní BSD socketů stojí za to aspoň v hrubých obrysech znát - vizte odkazy na Wikipedii níže.
TCP má poměrně velké množství parametrů - doby timeoutů, parametry „pomalého startu“, velikosti bufferů atd., UDP má sice parametrů méně, protože je jednodušší, ale přesto jich pár je. Jak už to v Linuxovém jádře s různými parametry bývá, mají své výchozí (default) hodnoty, které jsou nastaveny pomocí konstant v kódu jádra. Mnohé se však dají za běhu změnit pro celý systém resp. pro daný síťový namespace přes sysctl parametry (a nebo přes odpovídající virtuální soubor v procfs (/proc/sys/net/...). Příklad:
root@osboxes:~# sysctl net.ipv4 | grep tcp_
net.ipv4.tcp_abort_on_overflow = 0
net.ipv4.tcp_adv_win_scale = 1
net.ipv4.tcp_allowed_congestion_control = reno cubic
net.ipv4.tcp_app_win = 31
net.ipv4.tcp_autocorking = 1
...
net.ipv4.tcp_retries1 = 3
net.ipv4.tcp_retries2 = 15
net.ipv4.tcp_rfc1337 = 0
net.ipv4.tcp_rmem = 4096 131072 6291456
net.ipv4.tcp_rx_skb_cache = 0
net.ipv4.tcp_sack = 1
net.ipv4.tcp_slow_start_after_idle = 1
net.ipv4.tcp_stdurg = 0
net.ipv4.tcp_syn_retries = 6
net.ipv4.tcp_synack_retries = 5
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_thin_linear_timeouts = 0
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_tso_win_divisor = 3
net.ipv4.tcp_tw_reuse = 2
net.ipv4.tcp_tx_skb_cache = 0
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_wmem = 4096 16384 4194304
net.ipv4.tcp_workaround_signed_windows = 0
A některé parametry lze měnit přes BSD sockets API pro každé spojení. Nebudeme teď opět zabíhat do detailů, nicméně je dobré podotknout, že parametry TCP a UDP protokolu mají význam pro výkon. Výchozí hodnoty většinou fungují docela dobře pro běžné nasazení jako pracovní stanice a nebo server. Přesto dřív či později každý admin linuxových serverů dojde k tomu, že bude potřebovat něco změnit či vylepšit kvůli zvláštním aplikacím a nebo výkonu celého systému. K tomu se ale dostaneme dále.
Odkazy:
- https://en.wikipedia.org/wiki/IP_tunnel
- https://cs.wikipedia.org/wiki/Generic_Routing_Encapsulation
- https://en.wikipedia.org/wiki/Generic_Routing_Encapsulation
- https://cs.wikipedia.org/wiki/Berkeley_sockets
- https://en.wikipedia.org/wiki/Berkeley_sockets
- https://bird.network.cz/
- https://www.quagga.net/
- https://keepalived.readthedocs.io/en/latest/index.html
- (https://www.kernel.org/doc/Documentation/sysctl/
- https://www.kernel.org/doc/Documentation/networking/