Nastavení síťového stacku v Linuxu
| Stránky: | CZ.NIC Moodle |
| Kurz: | Síťování v Linuxu |
| Kniha: | Nastavení síťového stacku v Linuxu |
| Vytiskl(a): | Nepřihlášený host |
| Datum: | pondělí, 15. června 2026, 12.08 |
Loopback, localhost
Ještě jsme se nezmínili o rozhraní lo. Loopback rozhraní slouží ke komunikaci „sám se sebou“. Typicky se tomuto rozhraní říká také localhost , podle zavedeného doménového jména, které se používá, chceme-li „mluvit sami se sebou“.
Rozhraní lo používá IP adresy z vyhrazeného rozsahu 127.0.0.0/8 pro IPv4, Linux obvykle používá adresu 127.0.0.1. Ostatní adresy z tohoto rozsahu lze použít také a dokonce se to dočkalo použití u systemd-resolved, kde se pro lokální DNS cache používá adresa 127.0.0.53. U IPv6 je pro loopback použitá právě jedna konkrétní adresa, která je tedy zároveň vyhrazeným rozsahem adres ::1/128.
Loopback potřebujeme, když se chceme například připojit na X server, aniž bychom řešili, zda máme nějakou externí konektivitu přes Ethernet nebo WiFi a na ní nějakou normální IP adresu. Nebo když se chceme připojit přes MySQL klienta na lokální MySQL server (a nejdeme přes UNIX socket, ale přes TCP/IP síť na localhost). Dejme tomu, že si chceme ověřit, že na našem experimentálním VM běží SSH server, aniž bychom se k němu připojili klientem:
root@osboxes:~# nc localhost 22
SSH-2.0-OpenSSH_8.2p1 Ubuntu-4ubuntu0.1
Ctrl-C
root@osboxes:~#
Distribuční skripty, NetPlan, NetworkManager
Každá (rozumná) distribuce systému GNU/Linux má nějaký způsob, jak uživateli usnadnit nastavení síťového stacku po startu sytému. Zejména jde o to automatizovat zbytečné repetitivní úlohy, které by musel uživatel dělat ručně po každém restartu. Další věc je, že se nastavení síťového stacku stává použitím těchto skriptů nebo programů více robustní - odolné proti různým chybám, dočasným výpadkům a podobně. Obojí má obrovský význam zejména u systémů, které jsou zavřeny v datacentrech a k jejichž konzoli se běžně nepřistupuje (ať už fyzicky nebo přes remote-management / KVM / IPMI /...).
My se spokojíme jen s rychlým přehledem a zaměříme se na Debian a Ubuntu, protože tyto dvě distribuce používáme v labech. Nicméně všechno další nastavení budeme dělat „ručně“ pomocí primárních nástrojů, jako jsou programy z iproute2 a podobně. To proto, že to jsou v relaci s vývojem distribucí a konfiguračních nadstaveb docela konzervativní nástroje, které se mění pomalu. A pak při řešení problémů a nebo nastavování labů jsou právě zapotřebí primární nástroje, kterými se přímo interaguje se síťovým stackem v reálném čase.
Pochopitelně když s pomocí primárních nástrojů vyřešíte daný problém a nebo nastavíte experimentální lab, je dalším krokem převést toto nastavení do produkčního systému - buď ekvivalentním nastavením ve skriptech a konfiguracích příslušné distribuce nebo zkrátka naprogramováním skriptu, kterým se systém pomocí primárních nástrojů uvede do požadovaného stavu. To je ale už celkem rutinní práce pro adminy a nezbývá, než odkázat na manuál distribuce, která se k tomuto účelu používá a vyzdvihnout programování v shellu.
Debian GNU/Linux
Debian Linux má sadu programů ifupdown. Prakticky to jsou programy ifup a ifdown. Tyto programy se málokdy spouští ručně - obvykle se o to postará při startu systemd. Nicméné ručně spustit jdou ifup <jméno rozhraní> nebo analogicky ifdown <jméno rozhraní>. Jak jména napovídají, ifup slouží k zapnutí a nakonfigurování síťového rozhraní a ifdown k dekonfiguraci a vypnutí.
Seznam síťových rozhraní a konstanty potřebné ke konfiguraci berou tyto programy ze souboru /etc/network/interfaces , případně z dalších souborů v adresáři /etc/network/interfaces.d/ (pokud soubor /etc/network/interfaces obsahuje příslušný řádek, kterým se načtou).
Příklad obsahu souboru /etc/network/interfaces vezmeme z našeho kontejneru c1 z kapitoly A.0:
root@c1:~# cat /etc/network/interfaces
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
# The loopback network interface
auto lo
iface lo inet loopback
auto eth0
iface eth0 inet dhcp
source /etc/network/interfaces.d/*
Příklad je samo-vysvětlující: Po startu se zkrátka správně nastaví loopback lo a pak se spustí DHCP klient na rozhraní eth. A opravdu:
root@c1:~# ps axf | grep dhcp
72 ? Ss 0:00 /sbin/dhclient -4 -v -i -pf /run/dhclient.eth0.pid -lf /var/lib/dhcp/dhclient.eth0.leases -I -df /var/lib/dhcp/dhclient6.eth0.leases eth0
Nicméně ifupdown umožňuje udělat poměrně složité konfigurace, nastavit různé částí síťového stacku nebo speciální rozhraní, jako například bridge. Umožňuje spouštět skripty před nebo po zapnutí každého rozhraní, konfigurovat směrovací tabulku atd.
Nebudeme však zabíhat do detailů - pokud jste uživatel Debianu a nebo vás to zajíma, není nic lepšího, než si přečíst primární dokumentaci.
Odkazy:
Ubuntu - NetPlan
Distribuce Ubuntu Server používá obdobný nástroj pro konfiguraci sítě - NetPlan. Ten je novější a k uchování konfigurace používá YAML sobory v adresáří /etc/netplan v našem případě to je:
root@osboxes:~# cat /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity'
network:
ethernets:
enp0s3:
dhcp4: true
version: 2
Změny v konfiguraci můžeme pomocí NetPlanu promítnout do stavu TCP/IP stacku příkazem netplan apply. Ve skutečnosti NetPlan sám přímo neinteraguje se síťovým stackem, ale používá jeden ze dvou backendů - NetworkManager a nebo systemd-networkd.
Přestože systemd-networkd má ambice stát se univerzálním nástrojem pro nastavení sítě na serverech a embedded zařízeních s Linuxem, stojí za to aspoň odkázat na jeho dokumentaci. Zatím univerzálním nástrojem není, přestože je přítomen všude, kde je systemd, což je dnes už drtivá většina mainstreamových distribucí.
Odkazy:
NetworkManager
Zatimco ifupdown a NetPlan jsou nástroje na nastavení sítě převážně pro použití na serverech, tak NetworkManager byl vymyšlen univerzálněji a hodí se proto k použití na linuxové pracovní stanici či laptopu. Perfektně podporuje WiFi (nastavit WiFi přes NetPlan nebo ifupdown jde také a je to v porovnání s ručním nastavením nakonec docela komfortní), autentizaci do drátové sítě přes 802.1X (to jde také ručně či s použitím jiných nástrojů, ale je to už práce) a také podporuje LTE modemy (opět to lze udělat jinak, ale je to víc práce). Naproti tomu je NetworkManager sám o sobě docela složitý a proto přináší i některé problémy.
Hlavní nevýhodou pro experimenty se síťováním na Linuxu je, že NetworkManager je vždy autoritativním nástrojem, který celkem nepredikovatelně kontroluje nastavení síťového stacku a uvádí jej do stavu, v jakém jej chce, podle své konfigurace, mít. Ruční nastavení a změny pomocí primárních nástrojů (například z balíčku iproute2) tedy NetworkManager při první příležitosti přepíše.
NetworkManager se nenastavuje (aspoň za normální situace) ručně úpravami konfiguračních souborů, nýbrž přes programy, které interagují s NetworkManager daemonem. Z konzole to jde například přes nmcli. V grafických prostředích - Gnome, KDE, XFCE atd., jsou pro NetworkManager k dispozici GUI aplety. Nicméně základní konfiguraci NetworkManager přece jen má v adresáři /etc/NetworkManager/.
Odkazy:
Ethernet, IP adresy a statický routing
Už jsme řešili, jak se zobrazuje stav rozhraní, základní statistiky, adresy na rozhraní a jak se zobrazuje směrovací tabulka. Slouží k tomu utilita ip ze sady iproute2. Podíváme se tedy na nastavení našeho kontejneru. Budeme nyní předstírat, že virtuální ethernetový pár, v kontejneru je to eth0, je Ethernet. Dokud se nezačneme pídit po hardwaru pomocí utilit mii-tool a nebo ethtool, tak je iluze celkem dokonalá.
root@osboxes:/home/osboxes# lxc-attach c1
root@c1:/# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 00:16:3e:73:04:49 brd ff:ff:ff:ff:ff:ff link-netnsid 0
root@c1:/# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:16:3e:73:04:49 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.3.9/24 brd 10.0.3.255 scope global dynamic eth0
valid_lft 3324sec preferred_lft 3324sec
inet6 fe80::216:3eff:fe73:449/64 scope link
valid_lft forever preferred_lft forever
root@c1:/# ip route
default via 10.0.3.1 dev eth0
10.0.3.0/24 dev eth0 proto kernel scope link src 10.0.3.9
DHCP a SLAAC
Z předchozí kapitoly víme, že, protože to je Debian Linux, tak používá ifupdown a jeho nastavení bylo nejjednodušší možné - zkráta se spustí DHCP klient na rozhraní eth0. Dejme tomu, že budeme chtít rozhraní dekonfigurovat a vypnout DHCP klienta.
Mimochodem, fungování protokolu DHCP a SLAAC jsme v předchozí kapitole moc neprobírali. Není to ale žádná věda - DHCP je protokol nad UDP a používá pro prvotní dotaz - DHCP discovery broadcast a komunikuje z IPv4 adresy „0.0.0.0“, což je speciální adresa, která říká „nemám žádnou adresu“.
SLAAC je funkce protokolu ICMPv6 a využívá toho, že každý interface má od začátku link-local adresu odvozenou z L2 adresy (MAC adresy u Ethernetu). Routery pravidelně a také na vyžádání posílájí RA (Router Advertisement, čili hlášení routeru), ze kterého se dá odvodit globální unicast adresa pro klienta a také výchozí brána, kterou má klient používat.
Odkazy:
Statické nastavení adres a default gateway
Dejme tomu tedy, že abychom si připravili půdu pro další experimenty, budeme chtít vypnout DHCP klienta v kontejneru c1 a nastavit síť ručně:
root@c1:/# ifdown eth0
Killed old client process
Internet Systems Consortium DHCP Client 4.4.1
Copyright 2004-2018 Internet Systems Consortium.
All rights reserved.
For info, please visit https://www.isc.org/software/dhcp/
Listening on LPF/eth0/00:16:3e:73:04:49
Sending on LPF/eth0/00:16:3e:73:04:49
Sending on Socket/fallback
DHCPRELEASE of 10.0.3.9 on eth0 to 10.0.3.1 port 67
root@c1:/# ip address
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 00:16:3e:73:04:49 brd ff:ff:ff:ff:ff:ff link-netnsid 0
root@c1:/# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default qlen 1000
link/ether 00:16:3e:73:04:49 brd ff:ff:ff:ff:ff:ff link-netnsid 0
root@c1:/# ip route
Teď zapneme vypnuté rozhraní eth0, nastavíme ručně IP adresu 10.0.3.9/24 na eth0 a default gateway 10.0.3.1 a vyzkoušíme, že nám opět funguje konektivita do Internetu (přes NAT na VM, ale k tomu se dostaneme až za chvili).
root@c1:/# ip link set up dev eth0
root@c1:/# ip address add 10.0.3.9/24 dev eth0
root@c1:/# ip route add default via 10.0.3.1
To je tedy nastavení a následuje kontrola:
root@c1:/# ip address
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:16:3e:73:04:49 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.3.9/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::216:3eff:fe73:449/64 scope link
valid_lft forever preferred_lft forever
root@c1:/# ping 8.8.8.8
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=116 time=14.5 ms
^C
--- 8.8.8.8 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 14.484/14.484/14.484/0.000 ms
Chytáky:
rozhraní musí být zapnuté (UP) - zda je rozhraní zapnuté je vidět ve výpisu
ip linkiip address: Hledáme řádek<BROADCAST,MULTICAST,UP,LOWER_UP>. Pokud rozhraní není zapnuté, lze sice všemožně nastavovat, ale stejně nefunguje. Bohužel to ale nefunguje vždy jako u síťového hardwaru (routerů a switchů), kde je zvykem, že pokud rozrhaní vypnete, tak se skutečné vypne PHY či optický modul a zcela se ztrátí vysílaný signál (rozhraní zkrátka zhasne). U běžných síťových karet může být HW aktivní i přes to, že je rozhraní v Linuxu vypnuté. Zdá se ale, že se chování moderních síťových karet začíná přibližovat routerům a switchům, nicméné spoléhat na to nelze.Když konfigurujeme adresu na rozhraní, nesmíme zapomenout na masku - v našem případě tedy 10.0.3.9/24 . Pokud masku nevyplníme explicitně, tak výchozí je /32 pro IPv4 a /128 pro IPv6, tedy jen jedna adresa. Tím pádem by nevznikla connected route a žádná další adresa ze subnetu 10.0.3.0/24 by nebyla dostupná. To se týká i adresy default gateway, tedy 10.0.3.1 a proto by nám tedy nefungovalo připojení k Internetu.
Nenechte se zmást chováním zastaralého nástroje ifconfig, ten opravdu masku často nepotřeboval, protože si masku dovozoval z takzvaných tříd IP adres. To je však překonaný koncept, který by se neměl pro IPv4 používat od dob zavedení CIDR (Classless Interdomain Routing) v roce 1994. Nemá to tedy smysl rozebírat, protože to je opravdu jen historická poznámka, která je dnes irelevantní, stejně jako nástroj ifconfig.
Statistiky
Ještě jsme slíbili statistiky (to je hlavní stížnost začátečníků na iproute2, že zatímco ifconfig zobrazoval statistiky přenosu a chyb, u nástroje ip chybí:
root@c1:/# ip -s link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
RX: bytes packets errors dropped overrun mcast
0 0 0 0 0 0
TX: bytes packets errors dropped carrier collsns
0 0 0 0 0 0
2: eth0@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 00:16:3e:73:04:49 brd ff:ff:ff:ff:ff:ff link-netnsid 0
RX: bytes packets errors dropped overrun mcast
707243 1450 0 0 0 0
TX: bytes packets errors dropped carrier collsns
159581 1332 0 0 0 0
VLAN, dummy a bridge
Už jsme probírali teorii, jak fungují VLANy. Teď si to i zkusíme v našem virtuálním prostředí. Budeme potřebovat další kontejner a použijeme jeden trik: přes „hloupé“ switche, které nemají nastavené VLANy a podobně i přes Linuxový bridge ve výchozím stavu procházejí rámce s 802.1Q tagem, jako by žádný tag neměly - switch se řídí jen cílovou MAC adresou.
VLAN rozhraní v Linuxu
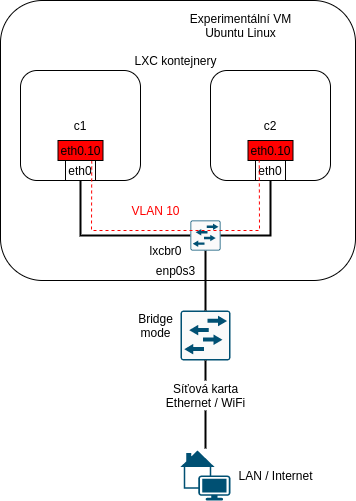
Takže vytvoříme a nastartujeme další kontejner:
root@osboxes:/home/osboxes# lxc-create -t download -n c2 -- -d debian -r buster -a amd64
Using image from local cache
Unpacking the rootfs
---
You just created a Debian buster amd64 (20201229_05:24) container.
To enable SSH, run: apt install openssh-server
No default root or user password are set by LXC.
root@osboxes:/home/osboxes# lxc-start c2
root@osboxes:/home/osboxes# lxc-info c2
Name: c2
State: RUNNING
PID: 75936
IP: 10.0.3.148
CPU use: 0.38 seconds
BlkIO use: 16.77 MiB
Memory use: 32.16 MiB
KMem use: 4.29 MiB
Link: vethWV90Pz
TX bytes: 1.24 KiB
RX bytes: 1.42 KiB
Total bytes: 2.66 KiB
Nyní můžeme vstoupit do obou kontejnerů, vytvořit VLAN rozhraní nad eth0 a dejme tomu, že na ně použijeme adresy ze subnetu 172.16.1.0/24. Každopádně musíme zvolit nový subnet tak, aby nám nekolidoval s ničím, co máme nastaveno na VM nebo v některém z kontejnerů, což naše volba splňuje. Adresy zvolíme následovně:
| Kontejner | Rozrhaní eth0.10 |
|---|---|
| c1 | 172.16.1.1/24 |
| c2 | 172.16.1.2/24 |
root@osboxes:/home/osboxes# lxc-attach c1
root@c1:/# ip link add link eth0 name eth0.10 type vlan id 10
root@c1:/# ip link set up dev eth0.10
root@c1:/# ip address add 172.16.1.1/24 dev eth0.10
root@c1:/# ip address
1: lo: <loopback,up,lower_up> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0@if4: <broadcast,multicast,up,lower_up> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:16:3e:73:04:49 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.3.9/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::216:3eff:fe73:449/64 scope link
valid_lft forever preferred_lft forever
3: eth0.10@eth0: <broadcast,multicast,up,lower_up> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:16:3e:73:04:49 brd ff:ff:ff:ff:ff:ff
inet 172.16.1.1/24 scope global eth0.10
valid_lft forever preferred_lft forever
inet6 fe80::216:3eff:fe73:449/64 scope link
valid_lft forever preferred_lft forever
Obdobně nastavíme kontejner c2:
root@osboxes:/home/osboxes# lxc-attach c2
root@c2:/# ip addr
1: lo: <loopback,up,lower_up> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0@if5: <broadcast,multicast,up,lower_up> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:16:3e:b2:ca:c6 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.3.148/24 brd 10.0.3.255 scope global dynamic eth0
valid_lft 3160sec preferred_lft 3160sec
inet6 fe80::216:3eff:feb2:cac6/64 scope link
valid_lft forever preferred_lft forever
root@c2:/# ip link add link eth0 name eth0.10 type vlan id 10
root@c2:/# ip link set up dev eth0.10
root@c2:/# ip address add 172.16.1.2/24 dev eth0.10
root@c2:/# ip address
1: lo: <loopback,up,lower_up> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0@if5: <broadcast,multicast,up,lower_up> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:16:3e:b2:ca:c6 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.3.148/24 brd 10.0.3.255 scope global dynamic eth0
valid_lft 3121sec preferred_lft 3121sec
inet6 fe80::216:3eff:feb2:cac6/64 scope link
valid_lft forever preferred_lft forever
3: eth0.10@eth0: <broadcast,multicast,up,lower_up> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:16:3e:b2:ca:c6 brd ff:ff:ff:ff:ff:ff
inet 172.16.1.2/24 scope global eth0.10
valid_lft forever preferred_lft forever
inet6 fe80::216:3eff:feb2:cac6/64 scope link
valid_lft forever preferred_lft forever
A teď zkontrolujeme, že konektivita opravdu funguje:
root@c2:/# ping 172.16.1.1
PING 172.16.1.1 (172.16.1.1) 56(84) bytes of data.
64 bytes from 172.16.1.1: icmp_seq=1 ttl=64 time=0.220 ms
^C
--- 172.16.1.1 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 0.220/0.220/0.220/0.000 ms
Nechme ping 172.16.1.1 z c2 ještě chvili běžet a podívejme se na datagramy, které prochází přes lxcbr0 ve VM. Připojíme se tedy na VM další SSH session a spustíme tcpdump:
root@osboxes:/home/osboxes# tcpdump -n -e -i lxcbr0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lxcbr0, link-type EN10MB (Ethernet), capture size 262144 bytes
00:50:58.402023 00:16:3e:b2:ca:c6 > 00:16:3e:73:04:49, ethertype 802.1Q (0x8100), length 102: vlan 10, p 0, ethertype IPv4, 172.16.1.2 > 172.16.1.1: ICMP echo request, id 107, seq 12, length 64
00:50:58.402057 00:16:3e:73:04:49 > 00:16:3e:b2:ca:c6, ethertype 802.1Q (0x8100), length 102: vlan 10, p 0, ethertype IPv4, 172.16.1.1 > 172.16.1.2: ICMP echo reply, id 107, seq 12, length 64
00:50:59.426033 00:16:3e:b2:ca:c6 > 00:16:3e:73:04:49, ethertype 802.1Q (0x8100), length 102: vlan 10, p 0, ethertype IPv4, 172.16.1.2 > 172.16.1.1: ICMP echo request, id 107, seq 13, length 64
00:50:59.426070 00:16:3e:73:04:49 > 00:16:3e:b2:ca:c6, ethertype 802.1Q (0x8100), length 102: vlan 10, p 0, ethertype IPv4, 172.16.1.1 > 172.16.1.2: ICMP echo reply, id 107, seq 13, length 64
00:51:00.450057 00:16:3e:b2:ca:c6 > 00:16:3e:73:04:49, ethertype 802.1Q (0x8100), length 102: vlan 10, p 0, ethertype IPv4, 172.16.1.2 > 172.16.1.1: ICMP echo request, id 107, seq 14, length 64
00:51:00.450087 00:16:3e:73:04:49 > 00:16:3e:b2:ca:c6, ethertype 802.1Q (0x8100), length 102: vlan 10, p 0, ethertype IPv4, 172.16.1.1 > 172.16.1.2: ICMP echo reply, id 107, seq 14, length 64
Ctrl-C
6 packets captured
6 packets received by filter
0 packets dropped by kernel
Všimněme si teď, co všechno nám výpis zachycených rámců z programu tcpdump říká:
- Vidíme MAC adresy, zdrojovou i cílovou pro každý rámec (abychom je viděli, pokužili jsme přepínač
tcpdump -e), můžeme MAC adresy zkontrolovat proti výpispůmip addressna obou kontejnerech. - Vidíme u všech rámců, jestli mají 802.1Q tag - to je pole
vlan 10ve vystupu. - Vidime IP adresy (zdrojovou a cílovou) každého IP datagramu, který se přenáší v ethernetovém rámci.
- Vidíme, že payload v IP jsou ICMP echo request a ICMP echo reply, tedy ping.
- Vidíme ID jednotlivých ICMP echo dotazů a odpovědí, takže je můžeme přesně asociovat s výstupem programu
ping.
Ještě stojí za to poznamenat, že historicky ke konfiguraci VLAN rozhraní sloužila utilita vconfig. Ta je však momentálně považována za zastaralou, podobně, jako ifconfig a nelze než doporučit se jí vyhnout a neučit se ji používat, přestože může vypadat na první pohled snadněji, než naznačená metoda přes moderní nástroje.
Odbočka: Linuxový bridge a VLAN
Celé to má ale jeden háček: zmiňovali jsme, že přes Linuxový bridge procházejí rámce s 802.1Q tagem, jako by to byl "hloupý" switch, tak je to celkem pravda, ale s jednou výjimkou: linuxový bridge není tak docela hloupý switch a rozumí multicastu, rozumí přihlašování do multicast skupin protokoly IGMP a MLD. V naší situaci nám to moc nevadilo, protože jsme nastavili pouze IPv4 adresy na oba kontejnery a ping je unicastová záležitost. MAC adresy si pro naše IP adresy kontejnery vyžádaly protokolem ARP a to je opět L2 broadcast. Mimochodem, ARP si také můžeme odchytit pomoci programutcpdump. Nejprve smažeme ARP záznam na c2 pro adresu kontejneru c1 a pak spustíme ping:
root@c2:/# ip neighbor
172.16.1.1 dev eth0.10 lladdr 00:16:3e:73:04:49 REACHABLE
10.0.3.1 dev eth0 lladdr 00:16:3e:00:00:00 STALE
10.0.3.9 dev eth0 lladdr 00:16:3e:73:04:49 STALE
root@c2:/# ip neighbor del 172.16.1.1 dev eth0.10
root@c2:/# ping 172.16.1.1
PING 172.16.1.1 (172.16.1.1) 56(84) bytes of data.
64 bytes from 172.16.1.1: icmp_seq=1 ttl=64 time=0.197 ms
64 bytes from 172.16.1.1: icmp_seq=2 ttl=64 time=0.153 ms
64 bytes from 172.16.1.1: icmp_seq=3 ttl=64 time=0.147 ms
64 bytes from 172.16.1.1: icmp_seq=4 ttl=64 time=0.179 ms
64 bytes from 172.16.1.1: icmp_seq=5 ttl=64 time=0.137 ms
64 bytes from 172.16.1.1: icmp_seq=6 ttl=64 time=0.147 ms
64 bytes from 172.16.1.1: icmp_seq=7 ttl=64 time=0.149 ms
^C
--- 172.16.1.1 ping statistics ---
7 packets transmitted, 7 received, 0% packet loss, time 85ms
rtt min/avg/max/mdev = 0.137/0.158/0.197/0.023 ms
Program tcpdump nám už musí běžet v druhé SSH session:
root@osboxes:/home/osboxes# tcpdump -n -e -i lxcbr0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lxcbr0, link-type EN10MB (Ethernet), capture size 262144 bytes
01:09:21.924102 00:16:3e:b2:ca:c6 > ff:ff:ff:ff:ff:ff, ethertype 802.1Q (0x8100), length 46: vlan 10, p 0, ethertype ARP, Request who-has 172.16.1.1 tell 172.16.1.2, length 28
01:09:21.924164 00:16:3e:73:04:49 > 00:16:3e:b2:ca:c6, ethertype 802.1Q (0x8100), length 46: vlan 10, p 0, ethertype ARP, Reply 172.16.1.1 is-at 00:16:3e:73:04:49, length 28
01:09:21.924183 00:16:3e:b2:ca:c6 > 00:16:3e:73:04:49, ethertype 802.1Q (0x8100), length 102: vlan 10, p 0, ethertype IPv4, 172.16.1.2 > 172.16.1.1: ICMP echo request, id 124, seq 1, length 64
01:09:21.924219 00:16:3e:73:04:49 > 00:16:3e:b2:ca:c6, ethertype 802.1Q (0x8100), length 102: vlan 10, p 0, ethertype IPv4, 172.16.1.1 > 172.16.1.2: ICMP echo reply, id 124, seq 1, length 64
01:09:22.926072 00:16:3e:b2:ca:c6 > 00:16:3e:73:04:49, ethertype 802.1Q (0x8100), length 102: vlan 10, p 0, ethertype IPv4, 172.16.1.2 > 172.16.1.1: ICMP echo request, id 124, seq 2, length 64
01:09:22.926145 00:16:3e:73:04:49 > 00:16:3e:b2:ca:c6, ethertype 802.1Q (0x8100), length 102: vlan 10, p 0, ethertype IPv4, 172.16.1.1 > 172.16.1.2: ICMP echo reply, id 124, seq 2, length 64
Ctrl-C
6 packets captured
6 packets received by filter
0 packets dropped by kernel
Tedy vidime, že první, co se stane, než c2 pošle první ICMP echo request, je sekvence ARP dotaz - odpověď. Všechno s VLAN tagem 10. Přesně, jak očekáváme.
Nicméně zpátky k problému, který jsme naznačili - přes Linuxový bridge nám nebude fungovat multicast. Takže nebude fungovat NDP, který potřebuje IPv6 místo ARPu, aby našel MAC adresy pro IPv6 adresy na broadcast doméně. Navíc to nebude fungovat trochu podivným způsobem - závisí to na tom, zda je v síti aktivní MLD querier. Nebudeme teď rozebírat detaily, ale je snadné to zkustit:
- Nastavte v obou kontejnerech na rozhraní eth0.10 IPv6 unicast adresy - například na c1 adresu 2001:db8::1/64 a 2001:db8::2/64 na kontejner c2.
- Zapněte MLD querierer na VM:
echo 1 > /sys/devices/virtual/net/lxcbr0/bridge/multicast_querier. - Vyčkejte přibližně 2 minuty, než querierer nainicializuje MLD.
- Vyčkejte až zmizí z ND cache na kontejnerech záznamy pro IPv6 adresy sousedů a zkuste ping z c1 na 2001:db8::2/64.
- Výsledkem by mělo být, že ping nebude fungovat, protože se kontejneru c1 nepovede zjistit MAC adresa k IPv6 adrese 2001:db8::2/64.
Řešení jsou dvě možné:
- udělat z Linuxového bridge opravdu hloupý switch pomocí
echo 0 >/sys/devices/virtual/net/lxcbr0/bridge/multicast_snooping - nadefinovat VLANy pro bridge a zapnout VLAN filtering: https://developers.redhat.com/blog/2017/09/14/vlan-filter-support-on-bridge/
bridge
O linuxovém bridgi už jsme toho napsali dost, ale ještě nepadlo, jak se takový bridge vytvoří a jak se spravuje. Zatím to za nás udělalo LXC.
Představa bridge je taková, že to je virtuální switch, do jednoho jeho virtuálního portu je připojen L3 interface, který bridge reprezentuje v systému - v našem případě to je lxcbr0 na naší VM. Dále pak jsou do bridge zapojeny další rozhraní (ať už fyzická - enp3s0 a nebo virtuální - u nás to jsou dva virtuální ethernetové páry), jako další „porty“.
Linuxový bridge se nastavuje dvojicí nástrojů: ip link z iproute2 a pak zvláštním nástrojem bridge. Oba tyto nástroje opět slouží jak k zobrazení stavu tak k manipulaci s bridgem:
root@osboxes:/home/osboxes# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 08:00:27:19:77:53 brd ff:ff:ff:ff:ff:ff
3: lxcbr0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 00:16:3e:00:00:00 brd ff:ff:ff:ff:ff:ff
4: vethwfg1Dt@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master lxcbr0 state UP mode DEFAULT group default qlen 1000
link/ether fe:08:30:5a:d7:82 brd ff:ff:ff:ff:ff:ff link-netnsid 0
5: vethWV90Pz@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master lxcbr0 state UP mode DEFAULT group default qlen 1000
link/ether fe:5a:c8:49:f8:82 brd ff:ff:ff:ff:ff:ff link-netnsid 1
root@osboxes:/home/osboxes# bridge link
4: vethwfg1Dt@enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master lxcbr0 state forwarding priority 32 cost 2
5: vethWV90Pz@enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master lxcbr0 state forwarding priority 32 cost 2
Ve výstupu ip link je důležité pole master, které u rozhraní, která jsou "porty" bridge, představuje právě tento podřízený vztah k bridgi. Ve výstupu bridge link vidíme pak aktivní rozhraní konkrétního bridge (což je vlastně obdobná informace, jakou bychom získali podrobným přečtením výstupu ip link). Nicméně interní stav bridge přes ip zobrazit nelze, na to je právě utilita bridge. S její pomocí můžeme zobrazit switch tabulku bridge pro unicast a multicast (ta je u nás prázdná) a také mapping VLAN. (Nicméně ten je relevantní, jen pokud je nakonfigurovaný VLAN filtering a ten my v tomto příkladu zaplý schválně nemáme):
root@osboxes:/home/osboxes# bridge fdb
33:33:00:00:00:01 dev enp0s3 self permanent
01:00:5e:00:00:01 dev enp0s3 self permanent
33:33:ff:19:77:53 dev enp0s3 self permanent
01:80:c2:00:00:00 dev enp0s3 self permanent
01:80:c2:00:00:03 dev enp0s3 self permanent
01:80:c2:00:00:0e dev enp0s3 self permanent
33:33:00:00:00:01 dev lxcbr0 self permanent
01:00:5e:00:00:01 dev lxcbr0 self permanent
33:33:ff:00:00:00 dev lxcbr0 self permanent
00:16:3e:00:00:00 dev lxcbr0 vlan 1 master lxcbr0 permanent
00:16:3e:00:00:00 dev lxcbr0 master lxcbr0 permanent
00:16:3e:73:04:49 dev vethwfg1Dt master lxcbr0
fe:08:30:5a:d7:82 dev vethwfg1Dt vlan 1 master lxcbr0 permanent
fe:08:30:5a:d7:82 dev vethwfg1Dt master lxcbr0 permanent
33:33:00:00:00:01 dev vethwfg1Dt self permanent
01:00:5e:00:00:01 dev vethwfg1Dt self permanent
33:33:ff:5a:d7:82 dev vethwfg1Dt self permanent
00:16:3e:b2:ca:c6 dev vethWV90Pz master lxcbr0
fe:5a:c8:49:f8:82 dev vethWV90Pz vlan 1 master lxcbr0 permanent
fe:5a:c8:49:f8:82 dev vethWV90Pz master lxcbr0 permanent
33:33:00:00:00:01 dev vethWV90Pz self permanent
01:00:5e:00:00:01 dev vethWV90Pz self permanent
33:33:ff:49:f8:82 dev vethWV90Pz self permanent
root@osboxes:/home/osboxes# bridge mdb
root@osboxes:/home/osboxes# bridge vlan
port vlan ids
lxcbr0 1 PVID Egress Untagged
vethwfg1Dt 1 PVID Egress Untagged
vethWV90Pz 1 PVID Egress Untagged
Jak tedy takový bridge vytvoříme? Předvedeme zde příklad, jak by šlo ručně vytvořit bridge, který pro nás udělal LXC (předem si jej však musíme smazat a pak všechno znovnu nastavit):
root@osboxes:/home/osboxes# ip link add name lxcbr0 type bridge
root@osboxes:/home/osboxes# ip link set lxcbr0 up
root@osboxes:/home/osboxes# ip address add 10.0.3.1/24 dev lxcbr0
A teď jak do nového bridge přidáme "porty" v podobě rozhraní virtuálních ethernetových párů LXC kontejnerů:
root@osboxes:/home/osboxes# ip link set vethwfg1Dt up
root@osboxes:/home/osboxes# ip link set vethwfg1Dt master lxcbr0
root@osboxes:/home/osboxes# ip link set vethWV90Pz up
root@osboxes:/home/osboxes# ip link set vethWV90Pz master lxcbr0
Odkazy:
Na závěr stojí za to upozornit na to, že historicky se bridge konfigurovaly a ovládaly utilitou brctl. Ta je však momentálně považována za zastaralou, podobně, jako ifconfig a nelze než doporučit se jí vyhnout a neučit s ji používat, přestože může vypadat na první pohled snadněji, než naznačená metoda přes moderní nástroje.
dummy rozhraní
Podobně jako se na Cisco routerech používají loopback interfacy pro nastavení adres, které představují endpoint nebo nějakou službu na routeru, tak se v Linuxu používají dummy rozhraní. Na Linuxu totiž nejde použít loopback podobně, jako na Cisco zařízeních, protože cokoliv, co v Linuxu pošlete na lo rozhraní, zůstává uvězněno na localhostu. Není to žádná magie, ve skutečnosti za to můžou Policy Based Routing pravidla, která jsou ve výchozím nastavení Linuxového kernelu, pro loopback rozhraní. Ještě se k tomu vrátíme v kapitole o PBR.
Dummy rozhraní tedy můžeme vytvořit, zapnout, nastavit na něj adresu a s pomocí statického routingu nebo pomocí směrovacích protokolů (například OSPF) můžeme zařídit jeho dostupnost pro ostatní hosty.
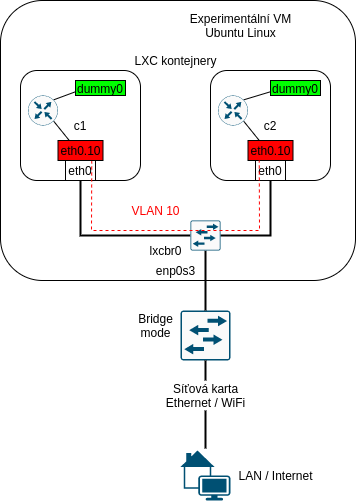
Dummy interface vytvoříme pomocí:
root@c1:/# ip link add dummy0 type dummy
root@c1:/# ip link
1: lo: <loopback,up,lower_up> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0@if4: <broadcast,multicast,up,lower_up> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 00:16:3e:73:04:49 brd ff:ff:ff:ff:ff:ff link-netnsid 0
3: eth0.10@eth0: <broadcast,multicast,up,lower_up> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 00:16:3e:73:04:49 brd ff:ff:ff:ff:ff:ff
6: dummy0: <broadcast,noarp> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 3a:52:c3:d0:68:50 brd ff:ff:ff:ff:ff:ff
Je tu ale přece jen trochu chyták: LXC kontejner nemusí mít práva na to, incializovat modul jádra dummy a proto můžete dostat chybu na první příkaz. To se dá vyřešit snadno tak, že modul zavedete ručně ve VM:
root@osboxes:/home/osboxes# modprobe -v dummy
insmod /lib/modules/5.4.0-28-generic/kernel/drivers/net/dummy.ko numdummies=0
Jakmile dummy rozhraní existují, můžeme je zapnout a dát na ně adresy stejně, jako na jakékoliv rozhraní. Z hlediska adresního plánu se k dummy rozhraní chováme stejně, jako k loopbacku na Ciscu, tedy dáváme na ně jednotlivé IP adresy (/32 pro IPv4 a /128 pro IPv6).
Pro další lab potřebujeme na obou kontejnerech nastavit jednu adresu na každé dummy rozhraní tak, aby nekolikdovala s žádným adresním prostorem, který jsme dosud použili. V našem případě jsme vybrali:
| Kontejner | dummy0 |
|---|---|
| c1 | 10.254.1.1/32 |
| c2 | 10.254.2.1/32 |
Statický IP routing
IP routing probihá v principu na každém uzlu IP sítě, minimálně proto, aby se uzel rozhodl, jaký traffic doručí přes connected route a co pošlet přes statické záznamy ve směrovací tabulce, například přes default route. K tomu není zapotřebí nic extra, prostě se nastaví správné záznamy do směrovací tabulky. Chceme-li však, aby Linux skutečně routoval, tedy že když dostane IP datagram na jednom rozhraní, provede vyhledání cílové adresy datagramu ve směrovací tabulce a najde-li next-hop, tak odešle datagram na MAC adresu next-hopu přes jiné síťové rozhraní, musí mít nastavené sysctl flagy: net.ipv4.conf.all.forwarding = 1 pro IPv4 a net.ipv6.conf.all.forwarding = 1, případně lze tento flag nastavit i pro jednotlivá rozhraní.
Předpokládejme, že máme nastavenou VLAN 10 a dummy interface z předchozích sekcí. Nyní chceme statickým routingem zařídit, abychom z c1 mohli komunikovat na adresu na dummy0 rozhraní na c2 a obráceně. To bez routingu nejde:
root@c1:/# ping 10.254.2.1
PING 10.254.2.1 (10.254.2.1) 56(84) bytes of data.
^C
--- 10.254.2.1 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 3ms
Začneme tím, že ověříme, zda máme adresy na rozhraních, jak jsme očekávali na kontejneru c1:
root@c1:/# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:16:3e:73:04:49 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.3.9/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::216:3eff:fe73:449/64 scope link
valid_lft forever preferred_lft forever
3: eth0.10@eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:16:3e:73:04:49 brd ff:ff:ff:ff:ff:ff
inet 172.16.1.1/24 scope global eth0.10
valid_lft forever preferred_lft forever
inet6 2001:db8::1/64 scope global
valid_lft forever preferred_lft forever
inet6 fe80::216:3eff:fe73:449/64 scope link
valid_lft forever preferred_lft forever
7: dummy0: <BROADCAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 32:98:14:e9:f2:94 brd ff:ff:ff:ff:ff:ff
inet 10.254.1.1/32 scope global dummy0
valid_lft forever preferred_lft forever
inet6 fe80::3098:14ff:fee9:f294/64 scope link
valid_lft forever preferred_lft forever
A taktéž na c2:
root@c2:/# ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:16:3e:b2:ca:c6 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.3.148/24 brd 10.0.3.255 scope global dynamic eth0
valid_lft 2458sec preferred_lft 2458sec
inet6 fe80::216:3eff:feb2:cac6/64 scope link
valid_lft forever preferred_lft forever
3: eth0.10@eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:16:3e:b2:ca:c6 brd ff:ff:ff:ff:ff:ff
inet 172.16.1.2/24 scope global eth0.10
valid_lft forever preferred_lft forever
inet6 2001:db8::2/64 scope global
valid_lft forever preferred_lft forever
inet6 fe80::216:3eff:feb2:cac6/64 scope link
valid_lft forever preferred_lft forever
4: dummy0: <BROADCAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether ae:08:23:bc:73:0b brd ff:ff:ff:ff:ff:ff
inet 10.254.2.1/32 scope global dummy0
valid_lft forever preferred_lft forever
inet6 fe80::ac08:23ff:febc:730b/64 scope link
valid_lft forever preferred_lft forever
Potřebujeme tedy přidat jeden záznam do směrovací tabulky na c1. Dejme tomu, že z adresního plánu víme, že v naší experimentální máme vyhrazený subnet 10.254.2.0/24 a uděláme tedy statickou route pro tento target (místo jedné konkrétní adresy z tohoto rozsahu). A vyzkoušíme, že nám jeden směr funguje (ping používá source adresu z nejbližšího rozhraní směrem k cíli, takže po nastavení zázamu do směrovací tabulky z jedné strany nám začně v tomto případě vzdálený dummy interface hned odpovídat):
root@c1:/# ip route add 10.254.2.0/24 via 172.16.1.2
root@c1:/# ping 10.254.2.1
PING 10.254.2.1 (10.254.2.1) 56(84) bytes of data.
64 bytes from 10.254.2.1: icmp_seq=1 ttl=64 time=0.297 ms
64 bytes from 10.254.2.1: icmp_seq=2 ttl=64 time=0.168 ms
64 bytes from 10.254.2.1: icmp_seq=3 ttl=64 time=0.251 ms
^C
--- 10.254.2.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 6ms
rtt min/avg/max/mdev = 0.168/0.238/0.297/0.056 ms
A to samé uděláme na na c2 v opačném směru. V tomto případě opět uděláme route šiřší, dle našeho (myšleného) adresního plánu 10.254.1.0/24:
root@c2:/# ip route add 10.254.1.0/24 via 172.16.1.1
root@c2:/# ping 10.254.1.1
PING 10.254.1.1 (10.254.1.1) 56(84) bytes of data.
64 bytes from 10.254.1.1: icmp_seq=1 ttl=64 time=0.362 ms
64 bytes from 10.254.1.1: icmp_seq=2 ttl=64 time=0.176 ms
^C
--- 10.254.1.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 3ms
rtt min/avg/max/mdev = 0.176/0.269/0.362/0.093 ms
Chytáky:
Na začátku této sekce jsme zmiňovali sysctl flagy
net.ipv4.conf.all.forwarding = 1pro IPv4 anet.ipv6.conf.all.forwarding = 1. Jenže my jsme toto nastavení zatím nepotřebovali. Trik je v tom, že pokud Linux doručuje datagram, který vznikl lokálně nebo je jeho cílová adresa na některém z rozhraní (klidně i na jiném rozhraní, než na které datagram dorazil), není forwarding flag potřeba a provoz se přesto doručí.Většina routerů na perimetru ISP sítí vynucuje BCP38 ( https://tools.ietf.org/html/bcp38 ). Ve zkratce jde o to, že pokud má uživatel na svou přípojku přidělenu adresu 192.168.0.100 ze subnetu 192.168.0.0/24, tak nesmí odesílat IP datagramy s (podvrženou) zdrojovou IP adresou mimo přidělený subnet. Takže například adresy se zdrojovou IP ze subnetu 10.254.0.0/16 budou zahozeny. Přesně se této metodě filtrování příchozího provozu říká „(unicast) Reverse Path Filtering„“ neboli uRPF. Aplikace uRPF má sama o sobě velké bezpečností výhody - zabraňuje se tím celé skupině útoků pomocí odrazu o nějakou veřejnou službu, jako je například DNS. Ale má to také negaitvní implikace - znemožňuje to asymetrický routing. V Internetu na úrovni ISP se uRPF už neuplatňuje, protože asymetrický routing je celkem běžná věc. O to důležitější je proto jeho vynucování na perimetru sítě. Podrobněji si to rozebereme v další kapitole. Tady to zmiňujeme proto, že na uRPF je třeba myslet i při vymýšlení routingu.
Odkaz:
Ještě než skončíme s touto kapitolou, stojí za to prověřit si, že nastavení statického IP routingu bezezbytku rozumíme. Podíváme se ještě jednou na směrovací tabulky:
root@c1:/# ip route
default via 10.0.3.1 dev eth0
10.0.3.0/24 dev eth0 proto kernel scope link src 10.0.3.9
10.254.2.0/24 via 172.16.1.2 dev eth0.10
172.16.1.0/24 dev eth0.10 proto kernel scope link src 172.16.1.1
Z pohledu c1 tedy máme lokálně připojený subnet (adresu) 10.254.1.1/32, ten však ve výpisu ip route nevidíme, protože je to jen jedna IP adresa a není proto zapotřebí pro ni vytvářet connected route. Kdybychom použili jinou masku, než /32, tak by connected route automaticky vznikla, podobně jako například pro spojovací síť 172.16.1.0/24. Ale víme, že pro dummy interface nemá smysl jiné nastavení, než pro ně přidělovat a konfigurovat jednotlivé IP adresy.
Chceme zajistit konektivitu na dummy interface na c2, který má adresu 10.254.2.1/32. Musíme tedy přidat záznam do směrovací tabulky na c1, který bude obsahovat tuto adresu.
Protože jsme udělali (dle našeho myšleného adresního plánu) širší routu pro /24 supernet, tak si můžeme položit otázku: Co se stane, když spustíme na c1 ping 10.254.2.2? Přirozeně, že žádné ICMP odpovědi nedostaneme, protože tato adresa není na c2 nastavena. Ale popořádku: Program ping na c1 datagram normálně odešle, protože routa pro cílovou síť existuje, next-hop je validní, nic tomu tedy nebrání. Přesvědčíme se, zda datagram odešel pomocí programutcpdump na c1:
root@c1:/# tcpdump -i eth0.10 -n
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0.10, link-type EN10MB (Ethernet), capture size 262144 bytes
14:00:40.013555 IP 172.16.1.1 > 10.254.2.2: ICMP echo request, id 4328, seq 1559, length 64
14:00:41.037638 IP 172.16.1.1 > 10.254.2.2: ICMP echo request, id 4328, seq 1560, length 64
14:00:42.061234 IP 172.16.1.1 > 10.254.2.2: ICMP echo request, id 4328, seq 1561, length 64
14:00:43.085170 IP 172.16.1.1 > 10.254.2.2: ICMP echo request, id 4328, seq 1562, length 64
14:00:44.109439 IP 172.16.1.1 > 10.254.2.2: ICMP echo request, id 4328, seq 1563, length 64
^C
5 packets captured
5 packets received by filter
0 packets dropped by kernel
Na c2 datagram normálně dorazí (opět ověříme pomocí root@c2:/# tcpdump -i eth0.10 -n). Jenže co dál? Odpověď žádná nechodí (v našem případě). Podívejme se ještě jednou na směrovací tabulku na c2:
root@c2:/# ip route
default via 10.0.3.1 dev eth0
10.0.3.0/24 dev eth0 proto kernel scope link src 10.0.3.148
10.254.1.0/24 via 172.16.1.1 dev eth0.10
172.16.1.0/24 dev eth0.10 proto kernel scope link src 172.16.1.2
Protože adresa 10.254.2.2 není nastavena na žádném rozhraní c2, uplatní se tedy jediný route záznam, který matchuje a to je default route. Takže datagram odchází směrem do Internetu (tedy na VM). To si ověříme opět pomocí tcpdump (tentokrát nedumpujeme na eth0.10, ale na eth0):
root@c2:/# tcpdump -i eth0 -n
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
14:07:02.989519 IP 172.16.1.1 > 10.254.2.2: ICMP echo request, id 4328, seq 1933, length 64
14:07:02.989566 IP 172.16.1.1 > 10.254.2.2: ICMP echo request, id 4328, seq 1933, length 64
14:07:04.013649 IP 172.16.1.1 > 10.254.2.2: ICMP echo request, id 4328, seq 1934, length 64
14:07:04.013703 IP 172.16.1.1 > 10.254.2.2: ICMP echo request, id 4328, seq 1934, length 64
^C
4 packets captured
4 packets received by filter
0 packets dropped by kernel
Takže naše pátrání bychom měli přesunout na VM a pravděpodobně zjistíme, že VM datagram přepošle dál podle své defaut route a teprve naše gateway v síti, do které je připojena naše pracovní stanice, datagram zahodí na základě uRPF. A skutečně, tcpdump na VM ukazuje, že tyto datagramy odcházejí směrem do Internetu, jak předepisují default route:
root@osboxes:/home/osboxes# tcpdump -i enp0s3 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
14:25:15.959577 IP 172.16.1.1 > 10.254.2.2: ICMP echo request, id 4328, seq 2998, length 64
14:25:16.983333 IP 172.16.1.1 > 10.254.2.2: ICMP echo request, id 4328, seq 2999, length 64
14:25:18.007433 IP 172.16.1.1 > 10.254.2.2: ICMP echo request, id 4328, seq 3000, length 64
^C
3 packets captured
3 packets received by filter
0 packets dropped by kernel
Je trochu škoda, že náš poskytovatel Internetu dodává closed-source routery, do kterých se nedá podívat, takže samotné zahození na uRPF nyní nemůžeme demonstrovat. Ale dostaneme se k tomu v další kapitole, kde si tento scénář ještě rozpracujeme.