Firewall a NAT
| Stránky: | CZ.NIC Moodle |
| Kurz: | Síťování v Linuxu |
| Kniha: | Firewall a NAT |
| Vytiskl(a): | Nepřihlášený host |
| Datum: | sobota, 4. července 2026, 04.18 |
Firewall a NAT
Na úvod je třeba říci, že v současné době (konec roku 2020) máme v Linuxu několik implementací funkcionality, kterou při troše zjednodušení označíme jako "firewall".
Mimochodem: Linux měl první "firewall" ve verzi 2.0 - ipfw/ipfwadm, což byl packetový filtr převzatý z FreeBSD. Následoval firewall ipchains ve verzi Linuxu 2.2 a po něm teprve přišel projekt Netfilter, který se ovládá pomocí (a spousta lidí jej zná pod názvem) iptables. Ani u iptables se vývoj nezastavil. Momentálně je v Linuxovém světě dvojice "frontendů" pro Netfilter v jádře: Moderní nft a vedle toho iptables. Aby to nebylo jednoduché, iptables jsou dvě různé odrůdy: iptables-nft, což je vlastně jen překladač pravidel z formátu příkazové řádky iptables to formátu nft. A pak jsou na některých systémech stále iptables-legacy, což jsou původní iptables, které interagují rovnou s jádrem (tedy ne přes modernější nft). My se podíváme na iptables i nft a protože u iptables nebudeme zabíhat do detailů, tak nám rozdíly mezi iptabes-nft a iptables-legacy nebudou vadit. Nicméně se hodí vědět, že tato komplikace existuje a že se můžeme ve specifických situacích nachytat na rozdíly. Také si je dobré uvědomit, že firewally nelze přímočaře kombinovat. Respektive v závislosti na verzích a použití kombinace nft a iptables-legacy vznikají různé nežádoucí interakce. My se jimi však nebudeme zabývat, protože obecně kombinovat firewally nemá smysl a je lépe se toho vyvarovat. Jediná úplně bezpečná kombinace je, že nft vidí pravidla vytvořená přes iptables-nft.
Vznikají však i novinky, stojící na úplně jiných technologických základech - projekt XDP (Express Data Path) umožňuje používat k filtrování eBPF a to těsně po opuštění síťové karty a ještě před tím, než packet vstoupí do síťového stacku a je pro něj vůbec alokována paměť. eBPF není zas tak úplná novinka, ve skutečnosti jde o přizpůsobení filtrovacího virtuálního stroje, který je v kernelu už docela dlouho, ale používal se především k filtrování při zachytávání packetů pomocí libpcap - to je backend, který používá nám známý tcpdump.
My se technologiemi, které umožňují obcházet Linuxový síťový stack (XDP, eBPF, DPDK, ...) teď zabývat nebudeme, ale přesto stojí za to upozornit na jejich existenci a zbývá předem podotknout, že výkonová omezení, o kterých budeme psát dále v souvislosti s Netfilterem, nejsou absolutní. K jejich překonání s pomocí pokročilých technologií, které obchází síťový stack, vede však celkem složitá cesta.
Odkazy:
Filtrování packetů
Než se zaměříme na Linuxové firewally musíme ještě rozebrat koncepty. Hlavní koncept je packetový filtr. To je kód, který stojí mimo síťový stack a před vstupem i během zpracování packetu může nezávisle provést testy a o PDU rozhodnout - zda se má zahodit, propustit dále nebo nějak změnit. Slovo packet a nebo ještě lépe PDU používáme proto, aby bylo jasné, že teď nemluvíme o žádné konkrétní vrstvě ISO/OSI modelu, protože filtrovat můžeme podle obsahu v L2, L3 nebo L4 hlavičkách nebo klidně i podle různých hodnot v přenášených datech.
Vedle nejčastějších rozhodnutí o packetu - propustit nebo zahodit, může packetový filtr označit packet značkou - ta se zapíše do doprovodných datových struktur pro packet v paměti kernelu, ale v samotném packetu se nijak neprojevuje. Značku pak lze využít v síťovém stacku. A packetový filtr může dokonce omezeným způsobem manipulovat s obsahem packetu. Výhodou je nezávislost a relativní jednoduchost, která může pomoci zabránit útokům na potenciální chyby v kódu síťového stacku. Nevýhodou je, že packetový filtr málokdy do důsledků rozumí protokolům, které filtruje. (Tím se liší od některých aplikačních firewallů, které fungují víc jako proxy servery, tedy efektivně komunikují nezávisle se klientem a se serverem a předávají mezi nimi data, po tom, co je sémanticky zvalidují).
Packetové filtry jsou v původním slova smyslu chápány jako bezstavové. Tedy že pro každý packet mohou vykonat sadu testů, ale krom obsahu právě zpracovávaného packetu nemají další informace, které by mohly k rozhodnutí pomoci.
Netfilter
Netfilter se filtruje pomocí pravidel a tato pravidla se uspořádávají do řetězců (chains) v pořadí, v jakém se mají vykonat. V Linuxu se používá sémantika, že když packet prochází určitou fází zpracování v síťovém stacku, je poslán na vstup příslušného řetězce pravidel. Například příchozí packet ze síťové karty, o kterém se ví, že jeho cílovou IP adresu má počítač na některém síťovém rozhraní, je vložen do tabulky filter do řetězce INPUT (v terminologii iptables).
Packet je pak testován pravidly z řetězce v daném pořadí, dokud není nalezena shoda s testovaným pravidlem a nebo není dosaženo konce řetězce. Je-li nalezena shoda s pravidlem, vykoná se akce tímto pravidlem určená - to může být například zahození packetu (DROP), nebo propuštění (ACCEPT), čili prakticky vrácení do síťového stacku do místa, odkud byl firewall zavolán. Možností akcí je víc, ale k tomu se dostaneme později.
Pokud testování dojde až na konec řetězce, vykoná výchozí akci (default) pro daný řetězec, kterou opět můžeme nastavit na ACCEPT nebo DROP.
Pravidla v řetězci mohou být například:
- je-li vstupní síťové rozhraní lo, akceptuj
- je-li zdrojová adresa 192.168.1.10, zahoď
- je-li vstupní rozhraní eth0, je-li zdrojová adresa ze subnetu 192.168.1.0/24, je-li packet TCP segment a cílový port je 22 nebo 80 nebo 443, akceptuj
- povol ICMP zprávy
- zahoď vše ostatní (to bude tedy výchozí pravidlo pro řetězec)
iptables
V syntaxi iptables tato pravidla budou vypadat takto:
iptables -A INPUT -i lo -j ACCEPT
iptables -A INPUT -s 192.168.1.10 -j DROP
iptables -A INPUT -i eth0 -s 192.168.1.0/24 -p tcp --match multiport --dports 22,80,443 -j ACCEPT
iptables -A INPUT -p icmp -j ACCEPT
iptables -P INPUT DROP
iptables je program, kterým manipulujeme s pravidly Netfilteru. Parametr -A znamená append, přidáváme jím tedy pravidlo na konec řetězce INPUT. -P znamená policy, tedy výchozí pravidlo pro chacin. Chybí zde ovšem specifikace, že manipulujeme s tabulkou filter - to ale psát nemusíme, protože to je výchozí hodnota. Kdybychom například manipulovali s tabulkou nat, napsat bychom to už za parametr -t museli:
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -j MASQUERADE
K tomu se ale dostaneme za chvíli.
Teď se hodí upozornit na to, že pravidla, která takto zadáme přes příkazovou řádku, se zapíší do kernelu a začnou se okamžitě vynucovat. Ale vydrží v kernelu jen dokud je nezměníme opět přes iptables nebo do restartu systému. Musíme se tedy pomocí skriptů a dalších utilit - iptables-save a iptables-restore postarat o zavedení pravidel po restartu. Některé distrubuce to udělají za nás. V Debian-based distribucích to bylo tradičně na administrátorovi.
Dále je dobré si všimnout, že sémantika pravidel je, že obsah jedno pravidla, to musí platit pro packet zároveň, aby mělo pravidlo shodu. Tedy v případě našeho třetího pravidla:
- vstupní rozhraní je eth0 a zároveň
- zdrojová adresa je ze subnetu 192.168.1.0/24 a zároveň
- packet je TCP segment a zároveň
- cílový port je 22 nebo 80 nebo 443 - tohle je trochu specialita, také se na to v
iptablesmusí použít speciální modulmultiport
Bez --match multiport bychom to museli napsat jako tři pravidla, kde by poučka o AND formě pravidel platila dokonale.
Ještě se bezprostředně hodí vědět, jak pomocí iptables zobrazíme aktivní pravidla. Je na to příkaz iptables -L -t <table>. Tabulku pomocí -t nemusíme specifikovat a v tom případě se opět zobrazí výchozí tabulka filter. Příklad:
root@c1:~# iptables -L -vxn
Chain INPUT (policy DROP 21 packets, 1448 bytes)
pkts bytes target prot opt in out source destination
1 82 ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0
0 0 DROP all -- * * 192.168.1.10 0.0.0.0/0
0 0 ACCEPT tcp -- eth0 * 192.168.1.0/24 0.0.0.0/0 multiport dports 22,80,443
0 0 ACCEPT icmp -- * * 0.0.0.0/0 0.0.0.0/0
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
Parametry -v (verbose) -x (exact) -n (numeric) jsem použil pro zpřehlednění výpisu a zamezení reverzním DNS dotazům na IP adresy ve výpisu, které by neúměrně zdržovaly vygenerování výstupu a stejně by ho v reálné situaci akorát znepřehlednily.
Odkazy:
nftables
Podíváme se teď na ta samá pravidla pro nftables. To má výhodu, že nftables mají konfigurační soubor s pravidly /etc/nftables.conf a k tomu utilitu nft, která umí konfigurační soubor načíst pomoci nft -f /etc/nftables.conf .
Naše pravidla tedy budou vypadat takto:
table ip filter {
chain INPUT {
type filter hook input priority filter; policy drop;
iifname "lo" counter accept
ip saddr 192.168.1.10 counter drop
iifname "eth0" meta l4proto tcp ip saddr 192.168.1.0/24 tcp dport {22,80,443} accept
meta l4proto icmp counter accept
}
}
Tato pravidla se čtou mnohem snáz, nicméně je tu několik koncepčních změn: v první řadě slovo counter vyjadřuje, že pro pravidlo, které má toto slovo před akcí (accept nebo drop) se bude počítat počet packetů a bytů v packetech, které měly s pravidlem shodu.
Další poměrně důležitá koncepční změna je meta l4proto icmp resp. meta l4proto tcp: nftables umožňují sice napsat ip protocol icmp a v tomto případě by to nevadilo. Problém vzniká u IPv6, kde v políčku Next Header může být hodnota pro ICMP a nebo tam může být hodnota identifikující následující IPv6 extension header. V tomto případě by se pak pravidlo ip6 nexthdr icmpv6 neshodovalo s packetem i když by za hlavičkou IPv6 extension header byl ICMPv6 datagram. A to se opravdu stává - Hop-by-Hop Extension Header se používá pro MLD - Multicast Listener Discovery. A když nefunguje MLD, nemusí fungovat ani Neighbor Discovery, takže nakonec nebude fungovat v podstatě nic.
Jestli má IPv6 nějakou chybu, která způsobuje jeho trochu pošramocenou pověst - že se záhadně rozbíjí a nikdo neví proč, tak tohle je přesně příklad věci, která funguje u IPv6 trochu složitěji, než u IPv4 a na kterou si člověk snadno naběhne a celé to začne dávat smysl až po delší chvíli čtení, studia a diskuzí, proč to stálo za to udělat trochu složitější, než u IPv4. Na druhou stranu nftables je moderní a zavedlo meta l4proto pro IPv4 i IPv6, aby se zjednodušila situace s výchozím a doporučované nastavení bylo správně pro IPv4 i pro IPv6.
Poté, co pravidla instalujeme do kernelu pomocí nft -f /etc/nftables.conf je můžeme snadno zobrazit i s aktuálními countery:
root@c1:~# nft list ruleset
table inet filter {
chain input {
type filter hook input priority filter; policy accept;
}
chain forward {
type filter hook forward priority filter; policy accept;
}
chain output {
type filter hook output priority filter; policy accept;
}
}
table ip filter {
chain INPUT {
type filter hook input priority filter; policy drop;
iifname "lo" counter packets 180 bytes 14996 accept
ip saddr 192.168.1.10 counter packets 0 bytes 0 drop
iifname "eth0" meta l4proto tcp ip saddr 192.168.1.0/24 tcp dport { 22,80,443} counter packets 0 bytes 0 accept
meta l4proto icmp counter packets 1 bytes 93 accept
}
chain FORWARD {
type filter hook forward priority filter; policy accept;
}
chain OUTPUT {
type filter hook output priority filter; policy accept;
}
}
Všimněte si, že pravidla v předchozích případech nebyla úplně praktická - nepovolovala například spojení navázaná z našeho serveru kamkoliv do Internetu. Přesně řečeno: V OUTPUT řetězci sice bylo vše povoleno, takže odchozí packety by odešly. Ale odpovědi od serverů v Internetu by byly zahozeny, ledaže by matchovaly jedno z povolujících pravidel a to v našem případě znamená jen jedno pravidlo, které povoluje spojení na HTTP, HTTPS a SSH server. Můžeme to zachránit bezstavově tak, že pro protokol TCP povolíme všechny příchozí packety (TCP segmenty), krom těch, které navazují nové spojení a tedy mají nastaven flag SYN=1. To uděláme v iptables takto:
iptables -A INPUT -p tcp ! --syn -j ACCEPT
A pro nftables to bude v tabulce ip filter v řetězci INPUT pravidlo:
meta l4proto tcp tcp flags & (fin|syn|rst|ack) != syn counter accept
Jenže to sebou přece jen přináší problémy: z hlediska bezpečnosti to je nedokonalé. Umožňuje to útočníkům posílat TCP segmenty mimo normální pořadí, napadat běžící spojení a zkoušet se do nich vmísit a vůbec celé rozlišení, co jsou odpovědi na spojení navázané ven a co je pokračování spojení zvenčí, je od třetího packetu prakticky nemožné. U protokolu UDP nic, jako SYN flag není, takže tam jsou možnosti ještě víc omezené - prakticky můžete jen matchovat kombinací zdrojových a cílových adres a portů a jen podle nich datagram buď propustíte a nebo zahodíte.
Dejme tomu, že v příchozím směru by to bezstavově s protokolem TCP ještě šlo, za cenu složitějších pravidel a ústupků z bezpečnosti. V odchozím směru je to ale problém - tam už opravdu nerozlišíte, co je další segment běžícího spojení od vás ven a co je odpověď na nově navázané spojení zvenčí. Nemluvě o NATu, což je disciplína, ve které Linux vyniká, ovšem jen díky stavovému zpracování packetů - conntracku.
Zatím jsme se zabývali jen nejjednodušším případem - filtrování packetů v tabulce filter v řetězci INPUT. Netfilter má však mnoho výchozích řetězců a vedle toho umožňuje definovat vlastní řetězce uživateli. Průchod packetu firewallem je mnohafázový proces a rozebereme jej podrobněji v závěrečné kapitole.
Odkazy:
Stavové sledování spojení (connection tracking)
Bezstavový packetový filtr neví, zda je daný packet součástí nějakého běžícího TCP spojení nebo jestli je součástí nějakého řetězce UDP datagramů, který představuje souvislou transakci. Zde se hodí připomenout, že i když UDP nemá explicitní začátek a konec spojení, mnohé služby, které UDP používají, fungují obdobně jako krátce trvající TCP spojení. Nakonec i protokol QUIC (známý též jako HTTP/3) používá UDP místo TCP.
Vedle toho jsou ale UDP protokoly, které se zcela vymykají běžné sémantice navázání spojení, komunikaci přes tento kanál a následnému ukončení spojení. Například dnes už zastaralé, ale stále občas používané NFSv2 používá UDP k přenosu vzdálených volání procedur (RPC), které jsou prakticky operacemi se vzdáleným filesystémem. A tato volání jsou realizována pomocí Sun / ONC RPC a s podporou programu portmap, což vede k tomu, že UDP porty pro přenos souborů přes NFSv2 se volí náhodně při každém restartu NFS serveru. Pro NFSv2 se tedy velmi těžko vymýšlí pravidla pro packetový filtr.
Jiný příklad z opačného spektra jednorázových interakcí je protokol DNS ve své části mezi autoritativním a rekurzivním serverem. Tím myslíme to, že klient má nastaven rekurzivní server a toho se podle potřeby ptá na domény, které potřebuje přeložit na IP adresy. Tento rekurzivní server může klientovi odpovídat z cache, pokud si z minulosti pamatuje relevantní odpovědi (a jsou-li stále platné). Pokud rekurzivní server odpověď neví, kontaktuje řadu autoritativních serverů - začne v nejnižším bodě hierarchie domény, pro kterou má záznam ve své cache. V nejhorším případě začíná u DNS root serverů (ty má nakonfigurované staticky) a pokračuje dotazy až k poslednímu autoritativnímu serveru pro doménu nejvyššího řádu v dotazu. Na tom je ze síťového hlediska zajímavé, že rekurzivní server se autoritativního serveru zpravidla zeptá jediným UDP datagramem a jako odpověď běžně dostane také jeden jediný UDP datagram a tím komunikace na dlouho končí - rekurzivní server si odpověď uloží do cache, takže se po dobu platnosti záznamu nebude ptát na to samé znovu.
Linuxový conntrack
Vraťme se zpět k otázce: Jak zjednodušit konfiguraci firewallu a zároveň zvýšit úroveň bezpečnosti, kterou firewall poskytuje? Řekněme, že chceme povolit odpovědi, které přichází zvenčí na spojení, která jsme navázali my - tím tedy myslíme první odpověď (druhý TCP segment ve spojení s flagy SYN+ACK) a pak všechny další TCP segmenty s daty až do konce spojení. S connection trackingem to v iptables to uděláme snadno:
iptables -A INPUT -m state --state ESTABLISHED -j ACCEPT
Toto pravidlo se však hodí dát blízko začátku řetězce, takže je na zvážení použít míst parametru -A (append) možnost -I (insert), kterým lze pravidlo vložit na konkrétní pozici a bez argumentu specifikující pozici pak na začátek.
Pro nftables bude v tabulce ip filter v řetězci INPUT pravidlo:
ct state established counter accept
S jakými packety má tedy toto pravidlo shodu? Nebudeme zabíhat do úplných podrobností, ale v principu stav established představuje packety, která jsou součástí již navázaných spojení. Pro TCP má první packet (TCP segment s flagem SYN=1), kterým klient zahajuje navazování spojení, stav new. Jakmile server odpoví dle TCP three-way handshake druhým packetem ve spojení, tedy segmentem s flagy SYN=1, ACK=1, je spojení považováno za navázané a od druhého packetu včetně mají packety stav established. Podobně bychom mohli rozebrat ukončení spojení, které pro TCP znamená, že jak klient, tak server musí nezávisle vyslat segment s flagem FIN=1 a druhá strana musí tento segment potvrdit (ACK=1). Teprve když je spojení oboustranně uzavřeno, smaže se z tabulky spojení.
Pro UDP, kde není explicitní navazování a ukončování spojení formalizováno, mají stavy new a established přibližnou vypovídací hodnotu a v principu zachycují první packet s konkrétní čtveřicí - zdrojová IP adresa, cílová IP adresa, zdrojový port a cílový port - jako new a všechny následující packety s touto resp. inverzní (s prohozeným zdrojem a cílem) čtveřicí jako established. Ukončení spojení je jednoduše předpokládáno, pokud spolu strany spojení (určené čtveřicí adres a portů) nekomunikují déle, než timeout určený sysctl parametrem net.netfilter.nf_conntrack_udp_timeout_stream a ten má, mimochodem, u moderních kernelů výchozí hodnotu 120 s.
Samostatnou kapitolou by bylo rozebrání všech situací, které se mohou stát při navazování a ukončování spojení, pokud se některý z packetů, který tyto akce řídí, ztratí. Podobně je zajímavé havarijní ukončování TCP spojení jednostranně pomocí TCP segmentů s flagem RST=1. My se ale spokojíme s tím, že v drtivé většině situací můžeme věřit tomu, že packet se stavem new je zkrátka nově navazované spojení a established je pokračování spojení, které jsme předtím umožnili navázat jiným pravidlem.
Ještě se rychle zmiňme o stavu related. Ten značí, že packet sice není přímo součástní běžícího spojení, avšak je ve vztahu s běžícím spojením a je proto zpravidla rozumné propouštět nejen established, ale i related packety:
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
nebo
ct state { established, related } counter accept
Co přesně znamená to, že packet je ve vztahu s běžícím spojením? To může být například ICMP datagram, kterým se signalizuje chyba vzniklá v daném spojení - přesto na related se nedá úplně spoléhat a ICMP je lepší povolit explicitně. A pak to mohou být další kanály od existujícího hlavního spojení - příkladem je FTP, kde je nejdříve navázáno TCP spojení jako řídící kanál a pak se pro každý přenos souboru otevírá další spojení na jiných portech. Pokud není řídící kanál šifrovaný a pokud má Netfilter zapnutý FTP helper - modul, který odposlouchává příkazový kanál - dokáže pak označit packety náležící přenosu souboru jako related k navázanému příkazovému kanálu.
Odkazy:
Omezení a výkon
Tabulka spojení, kterou udržuje conntrack představuje poměrně složitou datovou strukturu, ve které se potenciálně vyhledává příslušný záznam pro každý zpracovávaný packet. To samo o sobě už je dost velký problém, protože si vezměme, že na 1Gb/s Ethernetu může přijít za sekundu přes 1,4 milionu packetů (když uvažujeme nejkratší možné IP datagramy). Na 10Gb/s, je to pak přes 14 milionů packetů za sekundu.
Aby toho nebylo málo, musí se pro každé nově otevřené spojení a každou novou UDP relaci udělat zápis do tabulky spojení a stejně tak pro každé skončené spojení a nebo zaniklou relaci se musí udělat výmaz. Linux momentálně používá kombinaci hashovací tabulky a linked-listu jako datovou strukturu pro udržování tabulky spojení a to samo o sobě znamená, že změny se musí částečně chránit lockem a snižují tedy multi-threadovou propustnost (byť i to se snaží autoři Netfilteru minimalizovat).
V neposlední řadě samo uložení tabulky v paměti zabírá prostor a to je pochopitelně docela odlišný problém na serveru s mnoha desítkami GB paměti a na SOHO routeru s 64 MB RAM. Linux má pro conntrack několik sysctl parametrů, kde tím nejzajímavějším je omezení na maximální počet záznamů v tabulce spojení - ve výpisu jej vidíme i s výchozí hodnotou:
root@r1:~/# sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 262144
V principu na normálně zatížené pracovní stanici, serveru a nebo domácím routeru vám bude pravděpodobně 256 k spojení stačit. Nicméně pokud Linux použijete jako firewall pro firmu z několika desítkami souběžně pracujících uživatelů, může se vám snadno stát, že v součtu tento limit překročí. Opravdu: jsou webové aplikace, které navazují stovky spojení s různými CDN servery, ze kterých pak sestavují Javascriptem výslednou stránku a tato spojení klidně drží desítky minut, dokud má uživatel záložku s danou stránkou otevřenou. Stačí, aby si několik desítek uživatelů spustilo několik desítek těchto aplikací, které navazují stovky spojení a k limitu se dostanete snadno. K tomu si uvědomte, že nesprávně ukončená spojení vám v tabulce zůstávají několik minut do timeoutu.
Krom toho samotný conntrack je docela lákavým cílem pro útoky odepřením služby (DoS) a vskutku se občas potkávají. Je ale diskutabilní, jesti tyto volumetrické útoky, které otevírají mnoho spojení, cílí na conntrack, na aplikace nebo na zastaralé síťové stacky. Každopádně pokud se tabulka spojení zaplní, vede to k tomu, že firewall nová spojení nepřijímá a zahazuje jejich packety. Dobrá zpráva je, že o tom píše docela jasnou zprávu do dmesg. Špatná zpráva je, že si toho těžko všimnete dřív, než vám začnou chodit stížnosti uživatelů, ledaže sledujete přes nějaký monitoring zaplnění tabulky z parametru net.netfilter.nf_conntrack_count a máte dobře nastavené alarmy.
Tím se tedy dostáváme k poslední úvaze: Conntrack je sice dobrý sluha, ale zlý pán. V některých situacích je výhodné vystačit si s bezstavovými pravidly a conntrack buď úplně vypnout. Případně jej lze vypnout selektivně pro konkrétní provoz pomocí zvláštního targetu NOTRACK, které lze použít v tabulce raw v chainu PREROUTING. Toto selektivní vypnutí conntracku má smysl například pro autortiativní DNS servery pro provoz na port 53/udp, který je beztak zpravidla tvořen pouze dvojicemi otázka a odpověď.
NAT
Linuxový conntrack je základem pro robustní implementaci NATu. NAT (Network Address Translation) řeší překlad provozu mezi dvěmi doménami adres toho samého protokolu a my se zaměříme na IPv4, kde se NAT masivně používá. Pro úplnost je třeba říci, že NAT je definován a také implementován i pro IPv6, ale k jeho použití s IPv6 je skutečně pádný důvod málokdy.
Nejběžnější použití NATu v Linuxu je svázáno s funkcí routeru, tedy že Linux stojí mezi dvěmi sítěmi, má ve směrovací tabulce vše potřebné, aby mohl komunikovat s adresami na obou stranách a má zapnutý forwarding pro daný protokol. Vyjděme z následujícího příkladu:
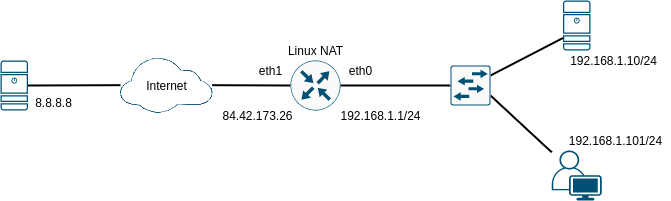
NAT můžeme rozdělit na SNAT (Source-NAT) a DNAT (Destination-NAT). V obou případech řešíme problém, že na levé straně od routeru máme globální unicast adresy v Internetu a na pravé straně jsou adresy privátní (podle RFC1918, případně RFC6598), které nelze v Internetu routovat. Řešením je, že pro všechny stanice v Internetu budeme na Linuxovém routeru překládat adresy ze sítě vpravo na adresu, kterou má router na rozhraní eth1 vlevo, která je global unicast a naopak, když přijde packet z Internetu pro některou stanici v síti vpravo, přeložíme cílovou adresu na rozhraní eth1 na adresu skutečného cíle v síti vpravo. V obou případech to ale není snadná úloha, protože v principu mapujeme několik adres v síti vpravo (subnet 192.168.1.0/24 v našem případě) na jednu globální unicast adresu vlevo (84.42.173.26). Abychom to mohli udělat, potřebujeme conntrack, který si zapamatuje čtveřici (IP adresa cíle, IP adresa zdroje, cílový port, zdrojový port) před a po překladu adres a dokáže tak rozpoznat odpověď na packet k příslušné čtveřici po překladu a doplnit tak cílovou adresu a cílový port na pravé straně.
SNAT / masquerade
Podívejme se nejprve na příklad SNATu (pro SNAT se také často používají jako synonyma "maškaráda", "masquerade" a nebo jen prostě NAT):
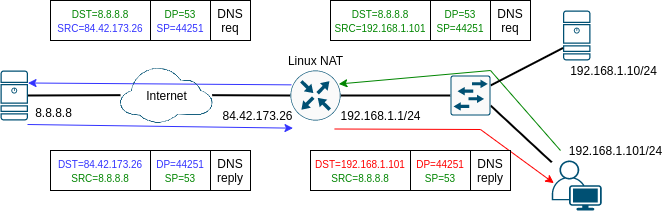
Než se pustíme do vysvětlování, řekněme rovnou, že této funkce dosáhneme jedním jediným pravidlem, kterým určíme překlad adres pro první packet spojení. Všechny další packety v obou směrech se už přeloží automaticky správně podle informací v tabulce conntracku. To jedno pravidlo v iptables bude:
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -o eth1 -j SNAT --to 84.42.173.26
a nebo ekvivalentní pravidlo pro nftables:
table ip nat {
chain POSTROUTING {
type nat hook postrouting priority 100; policy accept;
oifname "eth1" ip saddr 192.168.1.0/24 counter snat 84.42.173.26
}
}
V tomto případě tedy stanice 192.168.1.101 posílá DNS dotaz na server 8.8.8.8 z portu 44251 na port 53. Přesně takto DNS dotaz odejde ze stanice vlevo dole a předpokládáme, že v routovací tabulce stanice máme default GW 192.168.1.1, takže packet je doručen na náš Linuxový router. Na routeru předpokládáme, že máme default GW, která vede přes rozhraní eth1 na nějaký next-hop na straně poskytovatele Internetového připojení, který už pro nás není podstatný. Důležité je, že na základě cílové adresy routing rozhodne, že výstupní rozhraní pro náš packet je eth1. Teprve teď se uplatní pro packet pravidlo v POSTROUTING řetězci, které pro náš packet má shodu v obou kritériích - zdrojová adresa je v určeném subnetu a odchozí rozhraní je eth1. Provede se tedy překlad zdrojové adresy (SNAT), takže se vymění adresa 192.168.1.101 za adresu 84.42.173.26 a takto se packet skutečně odešle. V obrázku jsem změněné políčka TCP a UDP hlavičky obarvil ze zelené na modro. Možná si říkáte proč je modrý i zdrojový port, když se nezměnil. Pointa je, že se změnit může v závislosti na nastavení pravidla a dalších okolnostech. A krom toho, že se tento packet vyšle do Internetu, tak se také udělá záznam v tabulce spojení:
root@r1:~# conntrack -L
conntrack v1.4.5 (conntrack-tools): 53 flow entries have been shown.
...
udp 17 28 src=192.168.1.101 dst=8.8.8.8 sport=44251 dport=53 src=8.8.8.8 dst=84.42.173.26 sport=53 dport=44251 mark=0 use=1
Tento záznam vlastně obsahuje všechno, co potřebujeme vědět. Pro packety vstupující ze směru ve kterém bylo navázáno spojení (u nás v obrázku zprava) je první čtveřice s adres a portů před překladem (v obrázku je naznačené hlavičce packetu vše zelené). Pravidlo, které určuje překlad, přeloží zdrojovou adresu a ev. zdrojový port tak, aby byly platné v Internetu (v obrázku proto zmodrají). Server následně odpoví packetem, kde bude zeleno-modrá čtveřice obráceně (ze zdrojů se stanou cíle a naopak). Cílovou adresou odpovědi je tedy teď adresa rozhraní eth1 našeho routeru, která zajišťuje, že internetem odpověď dorazí na náš router. Tak se uplatní druhá část záznamu v conntrack tabulce, která obsahuje čtveřici pro odpovědi, která umožní rozpoznání packetu z daného spojení a jeho zpětné přeložení na odpovídající cílovou adresu a port (což je v našem příkladě červená dvojice na pravé straně).
Zbývá nám otázka, jak se liší masquerade (maškaráda) od SNAT: Z hlediska toku packetů nijak. Jediný rozdíl je, že zatímco u SNATu jsme museli do pravidla explicitně napsat na jakou adresu se má zdrojová adresa prvního packetu našeho spojení přeložit, tedy museli jsme do pravidel explicitně uvést v našem příkladě adresu 84.42.173.26, tak masquerade zkrátka nastaví primární adresu rozhraní, kterým packet odchází. Prakticky se pravidla změní jen minimálně:
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -o eth1 -j MASQUERADE
nebo pro nftables:
table ip nat {
chain POSTROUTING {
type nat hook postrouting priority 100; policy accept;
oifname "eth1" ip saddr 192.168.1.0/24 counter masquerade
}
}
V principu by SNAT stačil, ale nutil by člověka naskriptovat automatické změny SNAT pravidla v situaci, kdy se adresa na rozhraní směrem do Internetu může měnit, protože dynamicky přidělovaná protokolem DHCP, například. Naopak jen samotná akce masquerade by neumožnila ve složitějších scénářích volit jednu z více IP adres na kterou se má zdrojová adresa packetu přeložit a to je někdy potřeba, když se NATuje velká síť s mnoha uživateli.
Asymetrická cesta
Jak SNAT tak DNAT v Linuxu s pomocí conntracku závisí na tom, že přes Linux, který NAT provádí, prochází oba směry komunikace, protože v obou případech dochází k jednomu překladu adresy v jednom směru a k inverznímu překladu v druhém směru. Dejme tomu, že toto pravidlo nebude splněno pro DNAT, protože server ve vnitřní síti 192.168.1.10 bude mít default GW směřující do Internetu přes jiný router 192.168.1.254. Pokud bude tento router také Linux a dejme tomu, že bude mít nastaven SNAT pro packety z vnitřní sítě, podobně jako v předcházejícím odstavci. Pro TCP tento router stejně žádný SNAT neudělá, protože neuvidí začátek spojení - TCP segment s flagem SYN=1 a spojení bude tedy rovnou ve stavu invalid.
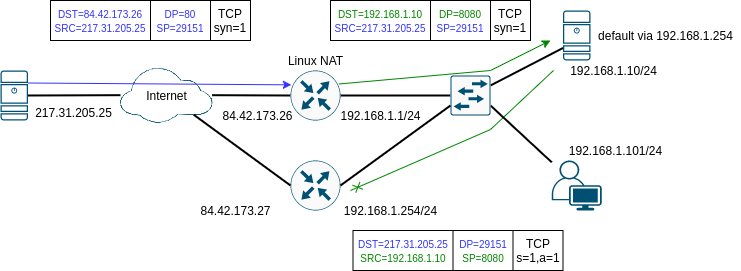
Dejme tomu, že ale bude provoz UDP nebo zkrátka z nějakého důvodu přes NAT na routeru 192.168.1.254 projde. Výsledkem bude jen to, že k původnímu odesílateli požadavku 217.31.205.25 dojde odpověď z jiné adresy, než na kterou poslal požadavek a proto bude odpověď zahozena, protože nebude odpovídat žádnému spojení nebo socketu, jak ukazuje následující obrázek.
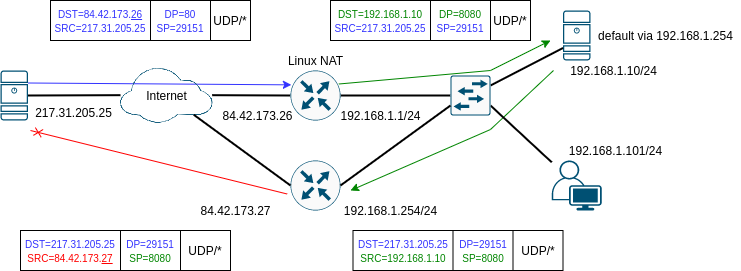
Toto pravidlo je obecné: Pokud máme Linuxový router se stavovým firewallem, musíme zajistit, aby přes něj chodily oba směry provozu, jinak nebude conntrack fungovat.
Mimochodem: K NATu může dojít víckrát za sebou na více různých routerech v cestě. Zkuste si to rozmyslet, že normálnímu spojení od klienta k serveru a odpovědím nazpět to vůbec nevadí. Jen je potřeba mít stále na paměti, že nesmí nastat asymetrická cesta a že tedy odpovědi musí jít zpět vždy přes ty samé NATující routery, jako dotazy.
DNAT
DNAT řeší opačný problém: Dejme tomu, že v našem příkladu ve vnitřní síti máme na stanici s IP adresou 192.168.1.10 spuštěný HTTP server na portu 8080/tcp a chceme jej zpřístupnit zvenčí. Bylo by pochopitelně možné celý server přenést do sítě, která je na hosting veřejně dostupných služeb připravená a přečíslovat jej na global unicast adresu. Dejme ale tomu, že toto řešení z nějakého důvodu nechceme realizovat a místo toho se rozhodneme pomocí překladu cílové adresy zpřístupnit HTTP službu z vnitřní sítě na adrese našeho Linuxového routeru a to na portu 80/tcp. Teď tedy DNATem přeložíme nejen adresu, ale i číslo portu, jak ukazuje následující obrázek:
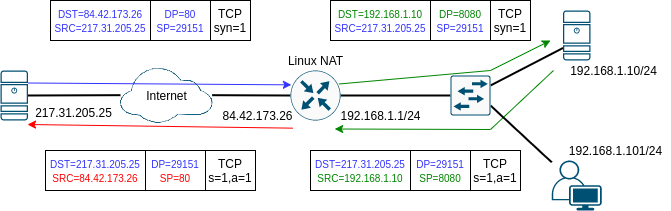
Tohoto přesměrování dosáhneme opět jediným pravidlem (za předpokladu, že směrovací tabulky zajišťují konektivitu v obou adresních doménách a že toku dat nestojí v cestě žádná pravidla v tabulce filter - k tomu se ještě vrátíme). Pravidlo pro iptables bude:
iptables -t nat -A PREROUTING -i eth1 -p tcp --dport 80 -j DNAT --to 192.168.1.10:8080
pro nftables bude ekvivaletní blok vypadat takhle:
table ip nat {
chain PREROUTING {
type nat hook prerouting priority 100; policy accept;
iifname "eth1" meta l4proto tcp tcp dport 80 counter dnat to 192.168.1.10:8080
}
}
Tentokrát už snad nemusíme zabíhat do tolika detailů a podíváme se jen na obrázek, který vlastně ukazuje první dva packety TCP spojení, které tentokrát navazuje klient 217.31.205.25 v Internetu nalevo na adresu 84.42.173.26. Zajímavá otázka může být, jak se klient dozví adresu našeho routeru v situaci, kdy to je domácí router a adresa na jeho eth1 je proměnlivá, protože se dynamicky přiděluje protokolem DHCP?: V této situaci se zpravidla používá nějaký druh dynamického DNS (DDNS), jehož smysl je v tom, že po přidělení nové adresy DHCP serverem na náš router dojde zvláštním protokolem k ohlášení nové adresy DDNS serveru a tato adresa se dočasně zapamatuje pro konkrétní (pevné) jméno, které máme pro náš router určené.
Klient se tedy připojuje TCP segmentem s flagem SYN=1 na adresu 84.42.173.26 na port 80. TCP segment dorazí na rozhraní eth1, čímž získá shodu s naším pravidlem v tabulce nat v PREROUTING řetězci, které změní cílovou adresu na 192.168.1.10 a cílový port na 8080. Tato změna nastane ještě před směrovacím rozhodnutím (proto PREROUTING), které by jinak rozhodlo o tom, že bude packet zpracován lokálně a poslán do síťového stacku. Protože ale včas došlo ke změně cílové adresy, směrovací rozhodnutí naopak vede k tomu, že je packet zpracován jako forwarding ve směru na interface eth0. Z hlediska serveru přichází normální HTTP request na port 8080 a server 192.168.1.10 vůbec neví, že se zdrojovou adresou v TCP segmentu 217.31.205.25 vlastně vůbec nemůže přímo bez NATu komunikovat. Proto server normálně odpoví a předpokládáme, že default GW na serveru odešle odpověď opět na náš router 192.168.1.1, který na základě informací v tabulce conntracku udělá tentokrát před routingem zpětný překlad (v obrázku zelenou adresu a port na červené) a packet odešle do Internetu. Klientovi tedy dorazí přesně takový packet, jaký očekával jako odpověď na navazování spojení. Všechny další TCP segmenty projdou dle tabulky conntracku tímto překladem adres a portů a proto se naváže a proběhne jinak zcela standardní TCP spojení.
Firewall
Předchozí dvě části vysvětlovaly na příkladech základy fungování Netfilteru a naznačovali jsme, že se díváme jen na konkrétní řetězce v tabulkách filter a nat a že úplný obrázek přijde později.
Průchod packetu firewallem
Pomůžeme si diagramem z dokumentu "Iptables Tutorial 1.2.1", původní autor: Oskar Andreasson, šířeno pod licencí GNU GPL 2.0:
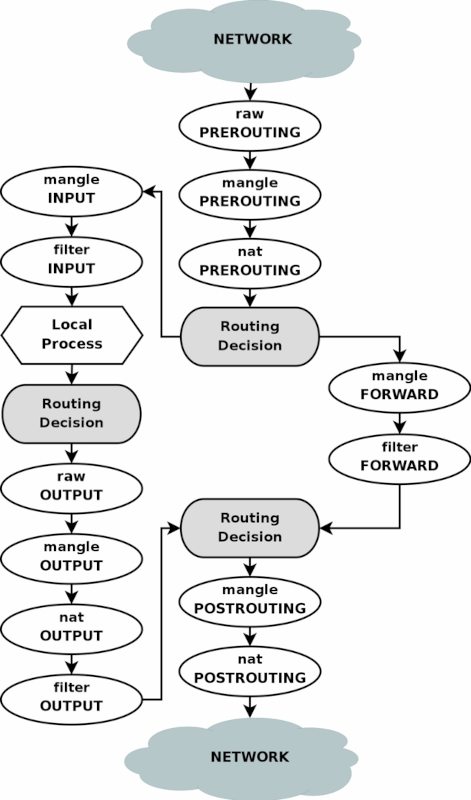
Je to sice jen přibližný diagram, ale nám skvěle poslouží. Podrobnější diagram je například na Wikipedii na stránce o Netfilteru, kterou uvádíme v odkazech.
Pro nás je podstatné si říci, co se dá ve které fázi zpracování packetu udělat a jak se liší cesty input , outputa forward.
V první řadě tedy packety, které přijdou ze síťového rozhraní
v tabulce raw a řetězci PREROUTING se zejména dá zabránit zpracování packetu conntrackem:
iptables -t raw -A PREROUTING -p udp --dport 53 -j NOTRACKnebo
table ip raw { chain PREROUTING { type filter hook prerouting priority raw; policy accept; meta l4proto udp udp dport 53 counter notrack } }v tabulce mangle a řetězci PREROUTING se dají packetům nastavovat například TOS (Type Of Service) flagy v IP hlavičce a nebo se dá nastavit fw-mark (to je bezrozměrný integer, značka kterou lze pak zpětně vyhledávat v dalších pravidlech a nebo jí lze použít jako klíč pro QoS nebo PBR - Policy Based Routing):
iptables -t mangle -A PREROUTING -p tcp --dport 22 -j TOS --set-tos 0x10 iptables -t mangle -A PREROUTING -p tcp --dport 80 -j MARK --set-mark 1nebo
meta l4proto tcp tcp dport 22 counter ip dscp set 0x04 meta l4proto tcp tcp dport 80 counter meta mark set 0x1V tabulce nat a řetězci PREROUTING se zpravidla dělá DNAT - to už známe.
Následuje směrovací rozhodnutí - před ním lze v pravidlech matchovat pouze vstupní rozhraní,
-i eth0například, nikoliv však výstupní rozhraní, protože to ještě není známo, dokud se neprovede toto směrovací rozhodnutí; zde se také určí další cesta packetu - buď přes INPUT řetězce do lokálního síťového stacku a nebo přes FORWARD řetězce na výstup - klíčem pro to pochopitelně je, zda je v tomto okamžiku cílová adresa packetu shodná s adresou na některém síťovém rozhraní (důležité je, že v tomto okamžiku - například v případě DNAT byla shodná když packet dorazil, ale my jsme jí včas změnili v tabulce nat v řetězci PREROUTING).Pokud se packet vydá cestou řetězců INPUT, tak v tabulce mangle jde udělat opět změny v havičkách a případně packet omarkovat.
V tabulce filter v řetězci INPUT je místo, kam patří pravidla, která chrání místní počítač - tedy v tomto místě by se mělo rozhodnout o tom, zda bude packet propuštěn do síťového stacku a nebo zahozen.
Naproti tomu cesta řetězci FORWARD je určená pro packety, které budou routingem přehozeny na next-hop, který byl nalezen při směrovacím rozhodnutí; tabulka mangle a řetězec FORWARD ničím nepřekvapí, jen narozdíl od fáze PREROUTING teď už víme, jaký bude výstupní interface a můžeme ho testovat na shodu v
iptablesnapříklad pomocí-o eth1.Řetězec FORWARD v tabulce filter je místo, kde zajišťujeme bezpečnost sítí, pro které je náš Linux routerem nebo firewallem.
Když se nyní podíváme na cestu packetu, co vznikl v lokálním síťovém stacku (ať je to podvěď na request, který k nám přišel a nebo je to request, kterým lokální síťový stack zahajuje spojení), začínáme v tabulce raw v řetězci OUTPUT, ten svým významem kopíruje řetězec PREROUTING, avšak tentokrát né pro příchozí, ale pro lokálně vzniklé packety; lze v něm tedy opět selektivně zabránit zpracování packetu conntrackem.
Řetězec OUTPUT v tabulce mangle svým významem nepřínáší překvapení - v tabulce mangle se dá měnit obsah vybraných hlaviček a nastavovat mark, v této situaci se u výstupního packetu někdy uplatňuje možnost nastavit TOC v IP hlavičce, TTL v IP hlavičce a nebo MSS v TCP hlavičce - smysl nastavení TOC je ladění výkonu, na TTL se zpravidla sahá jen v nezvyklých a krajních případech a manipulace s MSS má význam k obejdutí problémů s rozbitým PMTU discovery (vizte minulé kapitoly o ICMP), příklady:
iptables -t mangle -A OUTPUT -o eth1 -j TTL --ttl-set 32 iptables -t mangle -A OUTPUT -p tcp -o eth1 -j TCPMSS --set-mss 1460nebo
oifname "eth1" meta l4proto tcp counter tcp option maxseg size set 1460Pro nastavení TTL momentálně (konec roku 2020) nftables podporu nemají.
Řetězec OUTPUT v tabulce nat je místem, které jsem zatím nepotřeboval ani v nejpodivnějších scénářích v labech.
Řetězec OUTPUT v tabulce filter je místem, které chrání před únikem dat a lze v něm také snadno a rychle zabránit škodám pokud je váš server částečně vyhackován a posílá spousty útočných packetů do Internetu - to se často vídá na různých webhostingových serverech, když se hackerům povede zmanipulovat neprivilegovaně běžící webové skripty a posílat skrz ně různé druhy útoků; pochopitelně to má smysl jen když hackeři neovládnou root účet a i tak je to jen hotfix, aby se nemusel celý server odstavit, než se najde a odstraní hlavní příčina.
Pokud jde o společnou část na výstupu, která zpracovává jak routované, tak lokální packety, tak v řetězci POSTROUTING v tabulce mangle opět můžeme měnit TOC, TTL, MSS a teoreticky přidat mark, ale v tento okamžik už markování nemá žádný smysl, protože prakticky vše je už rozhodnuto.
A nakonec v tabulce nat v řetězci POSTROUTING se zpravidla dělá SNAT nebo maškarád.
Pro úplnost přikládáme složitější diagram z Wikipedie (autor: Jan Engelhardt, šířeno pod licencí [CC BY-SA 3.0]: https://creativecommons.org/licenses/by-sa/3.0 ).
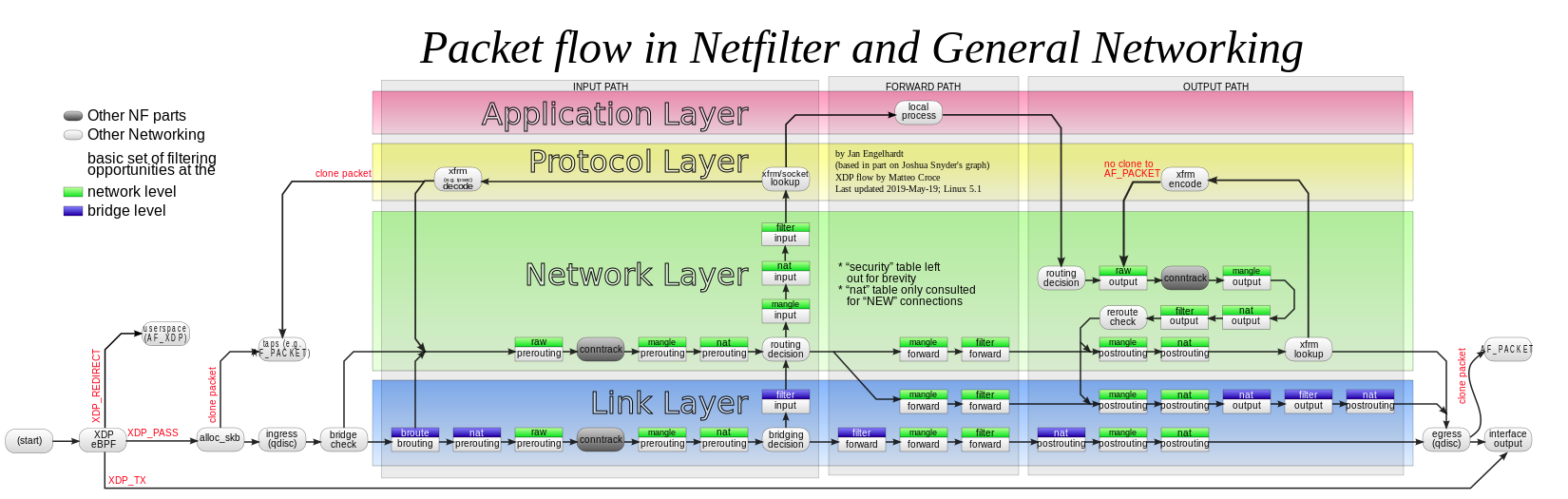
Tady stojí za upozornění, že jsou situace, kdy packet neprochází Linuxovým firewallem přímočaře, ale může se v jiné podobně vrátit - máme na mysli zejména situaci, kdy je packet odeslán do virtuálního rozhraní - tunelu a nebo je na něm provedena IPsec transformace. Přesto tyto okrajové případy už nepatří do základního přehledu a zůstaneme u připomenutí, že předcházející rozbor na základě prvního diagramu byl zkrátka zjednodušený.
Odkazy:
Pořadí pravidel v řetězcích
Vrátíme se teď na chvíli k pravidlům, která akceptují velké množství packetů a která jsme v příkladech psali vždy na co nejvyšší pozice v řetězcích. Máme na mysli například pravidla v INPUT řetězci z minulých příkladů:
- propusť vše, co přišlo na rozhraní lo -
iptables -A INPUT -i lo -j ACCEPT - propusť vše, co je dle conntracku established -
iptables -A INPUT -m state --state ESTABLISHED -j ACCEPT
Čím výše v řetězci tato pravidla dáme, tím dříve se najde shoda pro packety běžících spojení a tím dříve budou akceptovány a procházení pravidel bude ukončeno. Tím se tedy dostáváme k hlavní poučce ohledně Linuxového firewallu: na pořadí pravidel záleží! Pořadím v první řadě určujeme smysl pravidel v řetězci a za druhé jím ovlivňujeme výkon - čím víc pravidel je před pravidlem, které bude mít shodu, tím víc práce se musí pro packet udělat otestováním pravidel, která shodu nemají.
Proto je v situaci, kdy nemá pořadí vliv na smysl řetězce, lepší dát pravidla, jež mají shodu s větším množstvím packetů, co nejvýše. To je zejména situace, kdy v řetězci máme jen jeden druh akcí - ACCEPT nebo DROP. Naopak příklad, kde na pořadí záleží, jsou naše dvě pravidla z minulé sekce:
- je-li zdrojová adresa 192.168.1.10, zahoď
- je-li vstupní rozhraní eth0, je-li zdrojová adresa ze subnetu 192.168.1.0/24, je-li packet TCP segment a cílový port je 22 nebo 80 nebo 443, akceptuj
Dejme tomu, že tedy přijde na síťové rozhraní eth0 TCP segment se zdrojovou adresou 192.168.1.10, cílovou adresou shodnou s adresou na některém síťovém rozhraní, zdrojovým portem 55412 a cílovým portem 22. V našem případě bude tedy packet prvním pravidlem zahozen, druhé pravidlo se neuplatní. Kdyby však byla pravidla v opačném pořadí, tak bude packet propuštěn pravidlem (2) a pravidlo (1) se vůbec nikdy neuplatní.
Výkon a omezení
Už jsme rozebírali omezení a výkon conntracku a také fakt, že pravidla v řetězcích se zkouší od začátku do konce řetězce. Logicky tedy čím méně pravidel máme v jednotlivých řetězcích, tím rychlejší bude zpracování jednotlivého packetu a tím většího výkonu dosáhneme. Minimalizovat počet pravidel v řetězcích lze dvěma způsoby:
- Pro pravidla, která matchují velké množství konstant jednoho typu lze použít akcelerované datové struktury, kam se konstanty uloží a matchují se pak jedním pravidlem - nejznámější akcelerovaná struktura v Netfilteru je set, čili množina konstant - například IP adres, subnetů a nebo čísel portů.
- Pokud máme naopak složitá pravidla která matchují několik parametrů v konjunkci, lze si vzpomenout na převody logických formulí mezi normálními formami a uvědomit si, že z pravidel můžeme vytknout společné testy a vytvořit tak z pravidel strom uživatelem definovaných řetězců.
Pokud jde o akcelerované datové struktury - v iptables bylo jejich použití těžkopádné a vyžadovalo použití další utility ipset na správu množin - odkážeme na manuál a na příklady:
V nftables jsou naopak množiny velmi pohodlné na použití. Dokonce se v předchozích příkladech už párkrát vyskytly, aniž bychom jim věnovali pozornost. V nftables jsou dokonce dvě možnosti definice a použití setů - anonymní sety jsou zkrátka konstanty napsané do složených závorek:
iifname {"vlan100", "vlan110"} udp dport bootps counter accept
ip6 saddr 2001:db8::5054:ff:fe93:e74b tcp dport {22, 5665} counter accept
ip saddr {192.168.1.100, 192.168.1.110, 192.168.1.120} counter drop
Druhou možností jsou pojmenované množiny. Ty mají tu výhodu, že je lze testovat odkazem ve více pravidlech a navíc je lze snadno upravovat pomocí utility nft, aniž by se měnily samotná pravidla:
table ip filter {
set ssh_allowed {
type ipv4_addr
flags interval
elements = { 172.16.24.32, 192.168.224.192/28 }
}
chain INPUT {
type filter hook input priority 0;
policy drop;
ip saddr @ssh_allowed tcp dport 22 counter accept
}
}
Viditelnou nevýhodou je, že pojmenovaný set musíme explicitně definovat společně s typem a v našem příkladě, kde jsme chtěli používat jak subnety, tak jednotlivé IP adresy, tak jsme museli přidat flags interval. To pochopitelně trochu komplikuje použití (ovšem proti iptables a ipset to je pořád zlepšení) ale také to optimalizuje vygenerování a použití setu.
Vedle toho má nftables něco jako preprocesor pravidel, který lze použít ke zkonstruování pravidel i samotného obsahu pojmenovaných i nepojmenovaných setů:
define gw = 192.168.1.1
define http_allowed = { $gw, 10.150.0.0/24, 10.250.0.250 }
table ip filter {
set ssh_allowed {
type ipv4_addr
flags interval
elements = { $gw, 172.16.24.32, 192.168.224.192/28 }
}
chain INPUT {
type filter hook input priority 0;
policy drop;
ip saddr $http_allowed tcp dport 80 counter accept
ip saddr @ssh_allowed tcp dport 22 counter accept
}
}
To, co se s iptables muselo řešit složitými skripty, které vlastně generovaly finální pravidla na základě maker a abstrakce, lze s nftables udělat přímo v konfiguraci. Společně s použitím setů to z nftables dělá velmi dobrého nástupce. Na závěr této sekce se hodí podotknout, že akcelerované datové struktury nekončí jen u setů. nftables mají například i slovníky nebo lépe mapy, které se hodí například k řízení překladu adres. Pro podrobnější vysvětlení přidáváme následující odkazy:
- https://wiki.nftables.org/wiki-nftables/index.php/Sets
- https://wiki.nftables.org/wiki-nftables/index.php/Maps
Když se teď ještě na chvíli zastavíme u možnosti přerovnat pravidla do stromu, je třeba předně podotknout, že to je možnost spíše teoretická. Přesto rozdělení do více řetězců smysl mnohdy dává a na to je třeba v první řadě definovat vlastní řetězec a nasměrovat do něj konkrétní packety. Opět si to předvedeme na příkladě v nftables:
table inet filter {
chain FORWARD {
type filter hook forward priority 0; policy drop;
ct state invalid counter drop
iifname "vlan100" counter accept
oifname "vlan100" jump office_in
iifname "vlan101" goto wifi_out
oifname "vlan101" goto wifi_in
}
chain office_in {
ct state {established, related} counter accept
# accept connection to servers
ip daddr {10.1.1.10, 10.1.1.11} tcp dport {22, 80, 443} counter accept
meta l4proto icmp counter accept
}
chain wifi_in {
ct state {established, related} counter accept
# accept connection to servers
ip daddr {192.168.1.100, 192.168.1.101, 192.168.1.102} tcp dport {80, 443} counter accept
meta l4proto icmp counter accept
}
chain wifi_out {
# IOT outgoing connections are restricted
ip saddr {192.168.1.10, 192.168.1.20, 192.168.1.30, 192.168.1.40} ip daddr != 10.1.1.10 counter drop
# allow all others
counter accept
}
}
V první řadě je třeba upozornit na to, že zatímco do řetězce FORWARD jsou packety vkládány na základě jeho navázání na forward hook pomocí: type filter hook forward priority 0; policy drop;. V našem příkladě dále packety aktivně posíláme pomocí akce goto nebo jump do konkrétního námi-definovaného řetězce, pokud mají shodu s některým pravidlem v řetězci FORWARD s těmito akcemi. Rozdíl mezi jump a goto je ten, že jump vrátí packet z podřetězce zpět za pravidlo s jump, pokud v podřetězci nedojde ke shodě a rozhodnutí. Místo toho goto skok zpět neprovede a pokud v podřetězci, do kterého se přešlo pomocí goto, nebude shoda, tak se rovnou vykoná výchozí (policy) akce v nadřazeném řetězci.
Odkazy:
Design a bezpečnost
V tomto bodě máme probrané všechny základní technické aspekty Linuxového firewallu. Ještě ale nepadlo ani slovo o tom, co mají pravidla vyjadřovat.
Základní poučka v počítačové bezpečnosti je, že výchozí stav by měl být takový, že je všechno zakázáno a z toho se pak udělují výjimky pro aplikace a opodstatněné případy. Tento přístup by se dal ve firewallu snadno přenést do výchozích akcí drop ve všech řetězcích a do povolování výjimek pro konkrétní datové toky. Tento způsob by byl ovšem extrémní a spíš má smysl zkoncentrovat snahu o zabezpečení do řetězců v tabulce filter. V nich by opravdu měla být výchozí akce drop a uživatel by měl definovat datové toky, které potřebuje a ty pak explicitně povolit.
Pochopitelně pro pracovní stanici jsou požadavky docela jiné než pro server, který poskytuje konkrétní aplikaci přes HTTP a nikam dál se nepřipojuje, jen si stahuje z definovaného serveru updaty a používá třeba DNS a NTP opět z předem známých serverů. Pro takový server lze pravidla v tabulce filter definovat velmi precizně, možná klidně až paranoidně. Naopak u pracovní stanice obvykle neomezujeme kam se může připojovat, protože předpokládáme, že bude zdrojem velkého množství HTTP spojení na předem neznámé servery. To často vede k úvaze, že můžeme v tabulce filter v řetězci OUTPUT vše povolit a často to je nakonec jediná možnost, jak uživateli nekomplikovat život.
V dnešní době může i selhat poučka, že pracovní stanice je čistě klientská a že na ní tedy můžeme zakázat připojování zvenčí a to zejména proto, že programátoři často provozují svoje vývojové aplikace lokálně a uživatelé začali používat peer-to-peer spojení pro legitimní aplikace. Tato otázka nebývala předtím takový problém, protože s IPv4 RFC1918 adresami a NATem toho klientské stanice mnoho nedokázaly. S příchodem IPv6 se pro servery mnoho nezměnilo, ale pro klientské stanice to přináší opětovně problém správného vybalancování dostatečné ochrany uživatelů, proti degradaci dostupné konektivity do Internetu nesmyslnými omezeními. Na jednu stranu by byla velká škoda na firewallu zamezit point-to-point konektivitě, kterou IPv6 znovu zajišťuje všem stanicím v Internetu. Jedná se totiž o jednu z hlavních výhod IPv6 proti IPv4, které sice na začátku point-to-point konektivitu mělo, ale v devadesátých letech ji obětovalo kvůli nedostatku IPv4 adres. Na druhou stranu povolení spojení zvenčí na uživatelské stanice vyžaduje radikální změnu myšlení uživatelů i správců, kteří jsou bezmála 30 let ukolébáváni falešným pocitem bezpečí v sítích s oddělenou adresní doménou, protože používají IPv4 RFC1918 adresy a NAT.
Tady nám nezbývá než podotknout: NAT není bezpečnostní mechanismus! Veškerou bezpečnost by měl zařizovat firewall v tabulce filter. NAT se nakonec dá obelstít a lze přes něj různými triky dostat do vnitřní sítě různý provoz. Nejlepší je proto při návrhu firewallu na NAT nespoléhat a ideálně napsat pravidla pro IPv4 a IPv6 najednou a společně tak, aby předpokládaly a promyšleným způsobem se vyrovnaly s faktem, že protokol IPv6 zajišťuje end-to-end konektivitu.
Tady se hodí připomenout, že zatímco iptables má pravidla pro IPv4 a IPv6 striktně oddělená tím, že IPv4 se zadávají přes utilitu iptables, tak IPv6 mají svou utilitu ip6tables. Naproti tomu nftables umožňují nejen napsat IPv4 i IPv6 firewall do jednoho souboru, ale dokonce umožňují sdílet řetězce a zkrátka platí, že pokud testujeme na shodu IPv6 packet s pravidlem, které má test na IPv4 hlavičku, tak zkrátka shoda není možná a platí to pochopitelně i naopak pro IPv4 packet a IPv6 pravidlo.
Definice tabulky pro IPv4 je tedy:
table ip filter {
chain INPUT {
type filter hook input priority filter; policy accept;
...
}
}
Pro IPv6 to je:
table ip6 filter {
chain INPUT {
type filter hook input priority filter; policy accept;
...
}
}
A společná tabulka pro oba protokoly:
table inet filter {
chain INPUT {
type filter hook input priority filter; policy accept;
...
}
}
Odkazy:
Na závěr této sekce nám nezbývá, než zopakovat upozornění: Protokol ICMP (a ICMPv6) je zapotřebí pro správnou funkci ostatních protokolů. Jeho paušálním zakázáním máloco zlepšíme, ale hodně toho rozbijeme.
A úplně nakonec: Je třeba myslet na povolení provozu z a na loopback rozhraní lo.
Cvičení
Tato kapitola byla poněkud teoretická a i když obsahovala řadu příkladů, nic není lepší, než si teorii vyzkoušet v labu. Návrhy následujících cvičení vychází z labu, který jsme nastavili na konci minulé kapitoly, kde máme dva kontejnery, které spolu mohou komunikovat přes vyhrazenou VLAN a mají nastavené statické IP adresy na dummy rozhraních.
Bude se nám hodit nástroj nc (netcat), který nám umožní rychle a snadno udělat TCP server a TCP klienta na konkrétních portech. Pokud nc nemáme nainstalovaný, tak stačí apt-get install netcat.
Mimochodem: Linux má koncept privilegovaných portů: Na portech do 1023 včetně smí poslouchat jen procesy běžící jako root. Mimo jiné i proto HTTP servery jako například Apache dělají poměrně složitou rošádu s tím, že startují jako root, otevřou si socket na poslouchání na portu 80/tcp a pak se vzdají root privilegií a běží po zbytek času pod neprivilegovaným uživatelem. Pro nás to neznamená omezení, protože stejně v kontejnerech pracujeme jako root, ale hodí se to vědět.
Jednoduchý TCP server na portu 2345 spustíme pomocí (předem si ještě zjistíme IP adresu):
root@c1:~# ip addr
...
2: eth0@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
...
inet 10.0.3.9/24 brd 10.0.3.255 scope global dynamic eth0
root@c1:~# nc -l -p 2345
A připojíme se podobně snadno a vskutku program funguje jako cat co však nevypisuje obsah souborů na STDOUT a nezapisuje STDIN do souboru, nýbrž přijímá a posílá data přes síťový socket a co přijme vypíše na STDOUT a co přečte ze STDIN to pošle po síti. Napíšeme si tedy pár zpráv:
root@c2:~# nc 10.0.3.9 2345
Test z c2...
Test z c1...
<Ctrl+C>
a
root@c1:~# nc -l -p 2345
Test z c2...
Test z c1...
<Ukončení streamu>
Tento nástroj můžeme snadno použít k testování pravidel v následujících namětech na lab:
- Nastavte na c1 i c2 policy pro filtrer INPUT a FORWARD na DROP.
- Nastavte na c1 i c2 povolení pro odpovědi na navázaná spojení a vyzkoušejte na spojení do Internetu.
- Povolte na c1 i c2 provoz na a z loopback rozhraní a vyzkoušejte (
ping 127.0.0.1). - Povolte ICMP a ICMPv6 a vyzkoušejte (
pingna adresu c1 z c2 a naopak). - Povolte připojení z c2 na c1 na port 2345/tcp a vyzkoušejte pomocí netcatu.
- Vyzkoušejte přesměrování (DNAT) portu 2345/tcp na oblíbený HTTP server a zkuste stáhnout index.html pomocí utility
curlnebowget- nezapomeňte na to, že tohle bude fungovat jen pokud přes router, který dělá přesměrování jdou oba směry komunikace, nejlepší místo tedy bude přímo na VM, pokud to není jasné proč, zkuste si nakreslit obrázek a nebo nastavte přesměrování na c1, zkuste se na něj připojit z c2 a sledujte pomocítcpdumpus jakými adresami přichází odpovědi. - Vyzkoušejte scénář s aspoň třemi kontejnery, kde všechny kontejnery budou propojeny privátní VLAN a jen jeden kontejner bude firewall a NAT GW pro ostatní, nastavte SNAT, aby se kontejnery dostaly do Internetu a DNAT tak, aby se VM dalo připojit na
ncserver na některém z kontejnerů, zároveň kontejnery zabezpečte analogicky dle prvních čtyř cvičení.